

2018년 10월, SQuAD(Stanford Question Answering Dataset) 리더보드에 Human performance를 능가하는 점수로 1위 자리를 갱신한 모델이 나타나 엄청난 주목을 끌었다.
이른바, [사람보다 퀴즈를 잘 푸는 인공지능]이 나타났다는 소식은 딥러닝 자연어 처리 분야에 충격적인 뉴스였다.
구글에서 발표한 논문에 소개된 이 모델의 이름은 바로 BERT(Bidirectional Encoder Representations from Transformers)
이 모델은 340MB나 되는 엄청난 사이즈의 파라미터를 가진 모델을 수십 GB나 되는 코퍼스를 학습시켜 만든 pretrained model로서, SQuAD뿐 아니라 당시 거의 모든 자연어 처리 태스크의 SOTA(State-of-the-art)를 갱신하였다.
단순히 성능이 개선되어서만이 아니라, BERT는 엄청난 규모의 언어 모델(Language Model)을 pretrain하고 이를 어떤 태스크에든 약간의 fine-tuning만을 통해 손쉽게 적용하여 해결하는 제너럴 한 방식이 가능함을 입증하여, 자연어 처리 패러다임의 근본적인 변화를 불러왔다.
이후 수많은 후속 모델들이 BERT의 아이디어를 더욱 발전, 확장시켜 나가면서, 이전에는 기대할 수 없었던 자연어처리 기술 발달을 가속화해 가고 있다.
BERT 모델 구조를 살펴보고, Pretrained Model을 활용하여 한국형 SQuAD인 KorQuAD 태스크를 수행하는 모델을 학습해 보자.
이 과정을 통해 Contextual Word Embedding의 개념과 자연어처리 분야의 최근 트렌드인 전이 학습(Transfer Learning) 활용 방법까지 함께 숙지하도록 하자.
준비물
시작하기에 앞서 사용할 KorQuAD 데이터셋의 출처는 https://korquad.github.io/이다.
1. KorQuAD Task
KorQuAD 데이터셋 소개
KorQuAD(The Korean Question Answering Dataset, 한국어 질의응답 데이터셋)을 통해 자연어 처리 분야의 기계 독해(Machine Reading Comprehension, MRC) 태스크를 다루어 볼 것이다.
이 데이터셋은 미국 스탠퍼드 대학에서 구축한 대용량 데이터셋인 SQuAD를 벤치마킹하였다.
자연어 처리에 입문하게 되면 흔히는 감성분석 등의 Text Classification, 또는 Encoder-Decoder 구조의 모델을 통한 번역 태스크를 많이 다뤄볼 것이다.
자연어처리 분야에서 기계 독해 태스크는 머신이 자연어의 의미를 정확하게 이해하고 사람의 질문에 정확하게 답변할 수 있는지를 측정하는 아주 중요한 분야이다.
그래서 SQuAD 데이터셋은 언어 모델의 성능을 측정하는 가장 표준적인 벤치마크로 인정받고 있다.
두 데이터셋 모두 현재는 2.0으로 버전이 올라와 있다.
- 1.0과 2.0 모두 EM(Exact Match: 모델이 정답을 정확히 맞힌 비율)
- F1 score(모델이 낸 답안과 정답이 음절 단위로 겹치는 부분을 고려한 부분 점수)
- 1-example-latency(질문당 응답속도) 이상 3가지 척도로 모델을 평가
KorQuAD는 딥러닝 기반 QA(질의응답), 한국어 독해 능력을 측정하는 가장 중요한 태스크로 손꼽히고 있습니다. 그러면 이 데이터셋은 어떻게 구성되어 있는지 살펴보자.
Question 1.
KorQuAD1.0과 2.0의 주요한 차이점 3가지는 무엇인가?
(1) 문서의 길이 : 지문의 길이가 1.0은 한두 문단 정도지만 2.0은 위키백과 한 페이지 분량
(2) 문서의 구조 : 2.0에는 표와 리스트가 포함되어 있어 html 태그를 이해할 수 있어야 함
(3) 답변의 길이와 구조 : 1.0에서는 단어나 구 단위였으나, 2.0에서는 표와 리스트를 포함한 긴 영역의 답변 가능
아래 파일을 준비하자.
- ko_32000.model
- ko_32000.vocab
- bert_pretrain_32000.hdf5
- kowiki.txt.zip
# imports
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
import tensorflow.keras.backend as K
import tensorflow_addons as tfa
import os
import re
import numpy as np
import pandas as pd
import pickle
import random
import collections
import json
from datetime import datetime
import sentencepiece as spm
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
random_seed = 1234
random.seed(random_seed)
np.random.seed(random_seed)
tf.random.set_seed(random_seed)다운로드한 KorQuAD 데이터를 확인해 보자.
아래 print_json_tree() 메서드는 KorQuAD 데이터처럼 json 포맷으로 이루어진 데이터에서 리스트의 첫 번째 아이템의 실제 내용을 간단히 확인하는데 유용하다.
def print_json_tree(data, indent=""):
for key, value in data.items():
if type(value) == list: # list 형태의 item은 첫번째 item만 출력
print(f'{indent}- {key}: [{len(value)}]')
print_json_tree(value[0], indent + " ")
else:
print(f'{indent}- {key}: {value}')data_dir = '/content/drive/MyDrive/AIFFEL/data/bert_qna/data'
model_dir = '/content/drive/MyDrive/AIFFEL/data/bert_qna/models'
# 훈련데이터 확인
train_json_path = data_dir + '/KorQuAD_v1.0_train.json'
with open(train_json_path) as f:
train_json = json.load(f)
print_json_tree(train_json)- version: KorQuAD_v1.0_train
- data: [1420]
- paragraphs: [3]
- qas: [8]
- answers: [1]
- text: 교향곡
- answer_start: 54
- id: 6566495-0-0
- question: 바그너는 괴테의 파우스트를 읽고 무엇을 쓰고자 했는가?
- context: 1839년 바그너는 괴테의 파우스트을 처음 읽고 그 내용에 마음이 끌려 이를 소재로 해서 하나의 교향곡을 쓰려는 뜻을 갖는다. 이 시기 바그너는 1838년에 빛 독촉으로 산전수전을 다 걲은 상황이라 좌절과 실망에 가득했으며 메피스토펠레스를 만나는 파우스트의 심경에 공감했다고 한다. 또한 파리에서 아브네크의 지휘로 파리 음악원 관현악단이 연주하는 베토벤의 교향곡 9번을 듣고 깊은 감명을 받았는데, 이것이 이듬해 1월에 파우스트의 서곡으로 쓰여진 이 작품에 조금이라도 영향을 끼쳤으리라는 것은 의심할 여지가 없다. 여기의 라단조 조성의 경우에도 그의 전기에 적혀 있는 것처럼 단순한 정신적 피로나 실의가 반영된 것이 아니라 베토벤의 합창교향곡 조성의 영향을 받은 것을 볼 수 있다. 그렇게 교향곡 작곡을 1839년부터 40년에 걸쳐 파리에서 착수했으나 1악장을 쓴 뒤에 중단했다. 또한 작품의 완성과 동시에 그는 이 서곡(1악장)을 파리 음악원의 연주회에서 연주할 파트보까지 준비하였으나, 실제로는 이루어지지는 않았다. 결국 초연은 4년 반이 지난 후에 드레스덴에서 연주되었고 재연도 이루어졌지만, 이후에 그대로 방치되고 말았다. 그 사이에 그는 리엔치와 방황하는 네덜란드인을 완성하고 탄호이저에도 착수하는 등 분주한 시간을 보냈는데, 그런 바쁜 생활이 이 곡을 잊게 한 것이 아닌가 하는 의견도 있다.
- title: 파우스트_서곡# 검증데이터 확인
dev_json_path = data_dir + '/KorQuAD_v1.0_dev.json'
with open(dev_json_path) as f:
dev_json = json.load(f)
print_json_tree(dev_json)- version: KorQuAD_v1.0_dev
- data: [140]
- paragraphs: [2]
- qas: [7]
- answers: [1]
- text: 1989년 2월 15일
- answer_start: 0
- id: 6548850-0-0
- question: 임종석이 여의도 농민 폭력 시위를 주도한 혐의로 지명수배 된 날은?
- context: 1989년 2월 15일 여의도 농민 폭력 시위를 주도한 혐의(폭력행위등처벌에관한법률위반)으로 지명수배되었다. 1989년 3월 12일 서울지방검찰청 공안부는 임종석의 사전구속영장을 발부받았다. 같은 해 6월 30일 평양축전에 임수경을 대표로 파견하여 국가보안법위반 혐의가 추가되었다. 경찰은 12월 18일~20일 사이 서울 경희대학교에서 임종석이 성명 발표를 추진하고 있다는 첩보를 입수했고, 12월 18일 오전 7시 40분 경 가스총과 전자봉으로 무장한 특공조 및 대공과 직원 12명 등 22명의 사복 경찰을 승용차 8대에 나누어 경희대학교에 투입했다. 1989년 12월 18일 오전 8시 15분 경 서울청량리경찰서는 호위 학생 5명과 함께 경희대학교 학생회관 건물 계단을 내려오는 임종석을 발견, 검거해 구속을 집행했다. 임종석은 청량리경찰서에서 약 1시간 동안 조사를 받은 뒤 오전 9시 50분 경 서울 장안동의 서울지방경찰청 공안분실로 인계되었다.
- title: 임종석json 데이터의 실제 형태는 아래와 같이 json.dumps() 를 이용해 확인해 볼 수 있다.
print(json.dumps(train_json["data"][0], indent=2, ensure_ascii=False)){
"paragraphs": [
{
"qas": [
{
"answers": [
{
"text": "교향곡",
"answer_start": 54
}
],
"id": "6566495-0-0",
"question": "바그너는 괴테의 파우스트를 읽고 무엇을 쓰고자 했는가?"
},
{
"answers": [
{
"text": "1악장",
"answer_start": 421
}
],
"id": "6566495-0-1",
"question": "바그너는 교향곡 작곡을 어디까지 쓴 뒤에 중단했는가?"
},
{
"answers": [
{
"text": "베토벤의 교향곡 9번",
"answer_start": 194
}
],
"id": "6566495-0-2",
"question": "바그너가 파우스트 서곡을 쓸 때 어떤 곡의 영향을 받았는가?"
},
{
"answers": [
{
"text": "파우스트",
"answer_start": 15
}
],
"id": "6566518-0-0",
"question": "1839년 바그너가 교향곡의 소재로 쓰려고 했던 책은?"
},
{
"answers": [
{
"text": "합창교향곡",
"answer_start": 354
}
],
"id": "6566518-0-1",
"question": "파우스트 서곡의 라단조 조성이 영향을 받은 베토벤의 곡은?"
},
{
"answers": [
{
"text": "1839",
"answer_start": 0
}
],
"id": "5917067-0-0",
"question": "바그너가 파우스트를 처음으로 읽은 년도는?"
},
{
"answers": [
{
"text": "파리",
"answer_start": 410
}
],
"id": "5917067-0-1",
"question": "바그너가 처음 교향곡 작곡을 한 장소는?"
},
{
"answers": [
{
"text": "드레스덴",
"answer_start": 534
}
],
"id": "5917067-0-2",
"question": "바그너의 1악장의 초연은 어디서 연주되었는가?"
}
],
"context": "1839년 바그너는 괴테의 파우스트을 처음 읽고 그 내용에 마음이 끌려 이를 소재로 해서 하나의 교향곡을 쓰려는 뜻을 갖는다. 이 시기 바그너는 1838년에 빛 독촉으로 산전수전을 다 걲은 상황이라 좌절과 실망에 가득했으며 메피스토펠레스를 만나는 파우스트의 심경에 공감했다고 한다. 또한 파리에서 아브네크의 지휘로 파리 음악원 관현악단이 연주하는 베토벤의 교향곡 9번을 듣고 깊은 감명을 받았는데, 이것이 이듬해 1월에 파우스트의 서곡으로 쓰여진 이 작품에 조금이라도 영향을 끼쳤으리라는 것은 의심할 여지가 없다. 여기의 라단조 조성의 경우에도 그의 전기에 적혀 있는 것처럼 단순한 정신적 피로나 실의가 반영된 것이 아니라 베토벤의 합창교향곡 조성의 영향을 받은 것을 볼 수 있다. 그렇게 교향곡 작곡을 1839년부터 40년에 걸쳐 파리에서 착수했으나 1악장을 쓴 뒤에 중단했다. 또한 작품의 완성과 동시에 그는 이 서곡(1악장)을 파리 음악원의 연주회에서 연주할 파트보까지 준비하였으나, 실제로는 이루어지지는 않았다. 결국 초연은 4년 반이 지난 후에 드레스덴에서 연주되었고 재연도 이루어졌지만, 이후에 그대로 방치되고 말았다. 그 사이에 그는 리엔치와 방황하는 네덜란드인을 완성하고 탄호이저에도 착수하는 등 분주한 시간을 보냈는데, 그런 바쁜 생활이 이 곡을 잊게 한 것이 아닌가 하는 의견도 있다."
},
{
"qas": [
{
"answers": [
{
"text": "한스 폰 뷜로",
"answer_start": 402
}
],
"id": "6566495-1-0",
"question": "바그너의 작품을 시인의 피로 쓰여졌다고 극찬한 것은 누구인가?"
},
{
"answers": [
{
"text": "리스트",
"answer_start": 23
}
],
"id": "6566495-1-1",
"question": "잊혀져 있는 파우스트 서곡 1악장을 부활시킨 것은 누구인가?"
},
{
"answers": [
{
"text": "20루이의 금",
"answer_start": 345
}
],
"id": "6566495-1-2",
"question": "바그너는 다시 개정된 총보를 얼마를 받고 팔았는가?"
},
{
"answers": [
{
"text": "리스트",
"answer_start": 23
}
],
"id": "6566518-1-0",
"question": "파우스트 교향곡을 부활시킨 사람은?"
},
{
"answers": [
{
"text": "한스 폰 뷜로",
"answer_start": 402
}
],
"id": "6566518-1-1",
"question": "파우스트 교향곡을 피아노 독주용으로 편곡한 사람은?"
},
{
"answers": [
{
"text": "리스트",
"answer_start": 23
}
],
"id": "5917067-1-0",
"question": "1악장을 부활시켜 연주한 사람은?"
},
{
"answers": [
{
"text": "한스 폰 뷜로",
"answer_start": 402
}
],
"id": "5917067-1-1",
"question": "파우스트 교향곡에 감탄하여 피아노곡으로 편곡한 사람은?"
},
{
"answers": [
{
"text": "1840년",
"answer_start": 3
}
],
"id": "5917067-1-2",
"question": "리스트가 바그너와 알게 된 연도는?"
}
],
"context": "한편 1840년부터 바그너와 알고 지내던 리스트가 잊혀져 있던 1악장을 부활시켜 1852년에 바이마르에서 연주했다. 이것을 계기로 바그너도 이 작품에 다시 관심을 갖게 되었고, 그 해 9월에는 총보의 반환을 요구하여 이를 서곡으로 간추린 다음 수정을 했고 브라이트코프흐 & 헤르텔 출판사에서 출판할 개정판도 준비했다. 1853년 5월에는 리스트가 이 작품이 수정되었다는 것을 인정했지만, 끝내 바그너의 출판 계획은 무산되고 말았다. 이후 1855년에 리스트가 자신의 작품 파우스트 교향곡을 거의 완성하여 그 사실을 바그너에게 알렸고, 바그너는 다시 개정된 총보를 리스트에게 보내고 브라이트코프흐 & 헤르텔 출판사에는 20루이의 금을 받고 팔았다. 또한 그의 작품을 “하나하나의 음표가 시인의 피로 쓰여졌다”며 극찬했던 한스 폰 뷜로가 그것을 피아노 독주용으로 편곡했는데, 리스트는 그것을 약간 변형되었을 뿐이라고 지적했다. 이 서곡의 총보 첫머리에는 파우스트 1부의 내용 중 한 구절을 인용하고 있다."
},
{
"qas": [
{
"answers": [
{
"text": "주제, 동기",
"answer_start": 70
}
],
"id": "6566495-2-0",
"question": "서주에는 무엇이 암시되어 있는가?"
},
{
"answers": [
{
"text": "제1바이올린",
"answer_start": 148
}
],
"id": "6566495-2-1",
"question": "첫부분에는 어떤 악기를 사용해 더욱 명확하게 나타내는가?"
},
{
"answers": [
{
"text": "소나타 형식",
"answer_start": 272
}
],
"id": "6566495-2-2",
"question": "주요부는 어떤 형식으로 되어 있는가?"
},
{
"answers": [
{
"text": "저음 주제",
"answer_start": 102
}
],
"id": "6566518-2-0",
"question": "첫 부분의 주요주제를 암시하는 주제는?"
},
{
"answers": [
{
"text": "D장조",
"answer_start": 409
}
],
"id": "6566518-2-1",
"question": "제2주제의 축소된 재현부의 조성은?"
},
{
"answers": [
{
"text": "4/4박자",
"answer_start": 35
}
],
"id": "5917067-2-0",
"question": "곡이 시작할때의 박자는?"
},
{
"answers": [
{
"text": "고뇌와 갈망 동기, 청춘의 사랑 동기",
"answer_start": 115
}
],
"id": "5917067-2-1",
"question": "이 곡의 주요 주제는?"
},
{
"answers": [
{
"text": "D장조",
"answer_start": 409
}
],
"id": "5917067-2-2",
"question": "제 2주제에선 무슨 장조로 재현되는가?"
}
],
"context": "이 작품은 라단조, Sehr gehalten(아주 신중하게), 4/4박자의 부드러운 서주로 서주로 시작되는데, 여기에는 주요 주제, 동기의 대부분이 암시, 예고되어 있다. 첫 부분의 저음 주제는 주요 주제(고뇌와 갈망 동기, 청춘의 사랑 동기)를 암시하고 있으며, 제1바이올린으로 더욱 명확하게 나타난다. 또한 그것을 이어받는 동기도 중요한 역할을 한다. 여기에 새로운 소재가 더해진 뒤에 새로운 주제도 연주된다. 주요부는 Sehr bewegt(아주 격동적으로), 2/2박자의 자유로운 소나타 형식으로 매우 드라마틱한 구상과 유기적인 구성을 하고 있다. 여기에는 지금까지의 주제나 소재 외에도 오보에에 의한 선율과 제2주제를 떠올리게 하는 부차적인 주제가 더해지는데, 중간부에서는 약보3이 중심이 되고 제2주제는 축소된 재현부에서 D장조로 재현된다. 마지막에는 주요 주제를 회상하면서 조용히 마친다."
}
],
"title": "파우스트_서곡"
}KorQuAD 데이터셋 전처리 (1) 띄어쓰기 단위 정보관리
SQuAD, KorQuAD 데이터셋으로 모델을 구성하기 위한 전처리 과정은 다른 자연어 처리 태스크와 다소 다른 접근법이 있다.
코드를 실행하면서 예시를 살펴보자.
def _is_whitespace(c):
if c == " " or c == "\t" or c == "\r" or c == "\n" or ord(c) == 0x202F:
return True
return False# whitespace가 2개인 경우를 처리해야 함
string1 = '1839년 파우스트를 읽었다.'
string2 = '1839년 파우스트를 읽었다.'
string1[6:10], string2[7:11]('파우스트', '파우스트')위 두 문장에 대해 글자별로 띄어쓰기 영역 정보를 관리해 주려면 다음과 같이 약간 다르게 처리될 것이다.
word_tokens = []
char_to_word = []
prev_is_whitespace = True
# 첫번째 문장(string1)에 대해 띄어쓰기 영역 정보를 표시
for c in string1:
if _is_whitespace(c):
prev_is_whitespace = True
else:
if prev_is_whitespace:
word_tokens.append(c)
else:
word_tokens[-1] += c
prev_is_whitespace = False
char_to_word.append(len(word_tokens) - 1)
print(f'\'{c}\' : {word_tokens} : {char_to_word}')'1' : ['1'] : [0]
'8' : ['18'] : [0, 0]
'3' : ['183'] : [0, 0, 0]
'9' : ['1839'] : [0, 0, 0, 0]
'년' : ['1839년'] : [0, 0, 0, 0, 0]
' ' : ['1839년'] : [0, 0, 0, 0, 0, 0]
'파' : ['1839년', '파'] : [0, 0, 0, 0, 0, 0, 1]
'우' : ['1839년', '파우'] : [0, 0, 0, 0, 0, 0, 1, 1]
'스' : ['1839년', '파우스'] : [0, 0, 0, 0, 0, 0, 1, 1, 1]
'트' : ['1839년', '파우스트'] : [0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
'를' : ['1839년', '파우스트를'] : [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
' ' : ['1839년', '파우스트를'] : [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1]
'읽' : ['1839년', '파우스트를', '읽'] : [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2]
'었' : ['1839년', '파우스트를', '읽었'] : [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2]
'다' : ['1839년', '파우스트를', '읽었다'] : [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2]
'.' : ['1839년', '파우스트를', '읽었다.'] : [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2]word_tokens = []
char_to_word = []
prev_is_whitespace = True
# 두번째 문장(string2)에 대해 띄어쓰기 영역 정보를 표시
for c in string2:
if _is_whitespace(c):
prev_is_whitespace = True
else:
if prev_is_whitespace:
word_tokens.append(c)
else:
word_tokens[-1] += c
prev_is_whitespace = False
char_to_word.append(len(word_tokens) - 1)
print(f'\'{c}\' : {word_tokens} : {char_to_word}')'1' : ['1'] : [0]
'8' : ['18'] : [0, 0]
'3' : ['183'] : [0, 0, 0]
'9' : ['1839'] : [0, 0, 0, 0]
'년' : ['1839년'] : [0, 0, 0, 0, 0]
' ' : ['1839년'] : [0, 0, 0, 0, 0, 0]
' ' : ['1839년'] : [0, 0, 0, 0, 0, 0, 0]
'파' : ['1839년', '파'] : [0, 0, 0, 0, 0, 0, 0, 1]
'우' : ['1839년', '파우'] : [0, 0, 0, 0, 0, 0, 0, 1, 1]
'스' : ['1839년', '파우스'] : [0, 0, 0, 0, 0, 0, 0, 1, 1, 1]
'트' : ['1839년', '파우스트'] : [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
'를' : ['1839년', '파우스트를'] : [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
' ' : ['1839년', '파우스트를'] : [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1]
'읽' : ['1839년', '파우스트를', '읽'] : [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2]
'었' : ['1839년', '파우스트를', '읽었'] : [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2]
'다' : ['1839년', '파우스트를', '읽었다'] : [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2]
'.' : ['1839년', '파우스트를', '읽었다.'] : [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2]같은 코드이지만, '1839년' 다음의 공백 길이에 따라 두 문장의 영역 표시 결과가 조금 달라지는 것을 확인할 수 있다.
위에서 본 기능을 함수로 만들어 두면 아래 코드와 같다.
def _tokenize_whitespace(string):
word_tokens = []
char_to_word = []
prev_is_whitespace = True
for c in string:
if _is_whitespace(c):
prev_is_whitespace = True
else:
if prev_is_whitespace:
word_tokens.append(c)
else:
word_tokens[-1] += c
prev_is_whitespace = False
char_to_word.append(len(word_tokens) - 1)
return word_tokens, char_to_word위와 같은 방법으로 띄어쓰기 단위로 token을 정리한 후, word token 영역별로 유니크한 숫자(어절 번호)를 부여한다.
SQuAD 유형의 문제를 풀 때 글자 혹은 subword 단위로 token이 분리되는 것에 대비해서 원래 데이터가 띄어쓰기 단위로 어떠했었는지 word token 영역별로 추가 정보를 관리하면 도움이 된다.
아래와 같이 글자별로 word_token 영역을 표시해 주는 char_to_word list 를 관리해 둔다.
이 값은 현재 글자가 몇 번째 어절에 포함된 것이었는지를 말해 준다.
위 두 문장에 대해 방금 만든 함수를 다시 적용해 보자.
# 첫번째 문장(string1)에 대해 띄어쓰기 영역 정보를 표시
word_tokens, char_to_word = _tokenize_whitespace(string1)
for c, i in zip(list(string1), char_to_word):
print(f'\'{c}\' : {i}')
word_tokens, char_to_word'1' : 0
'8' : 0
'3' : 0
'9' : 0
'년' : 0
' ' : 0
'파' : 1
'우' : 1
'스' : 1
'트' : 1
'를' : 1
' ' : 1
'읽' : 2
'었' : 2
'다' : 2
'.' : 2(['1839년', '파우스트를', '읽었다.'], [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2])# 두번째 문장(string2)에 대해 띄어쓰기 영역 정보를 표시
word_tokens, char_to_word = _tokenize_whitespace(string2)
for c, i in zip(list(string2), char_to_word):
print(f'\'{c}\' : {i}')
word_tokens, char_to_word'1' : 0
'8' : 0
'3' : 0
'9' : 0
'년' : 0
' ' : 0
' ' : 0
'파' : 1
'우' : 1
'스' : 1
'트' : 1
'를' : 1
' ' : 1
'읽' : 2
'었' : 2
'다' : 2
'.' : 2(['1839년', '파우스트를', '읽었다.'],
[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2])KorQuAD 데이터셋 전처리 (2) Tokenize by Vocab
읽다, 읽었다, 읽어라, 읽고, 읽으려면, 읽다가....
이 모든 단어를 전부 단어 사전에 추가하려면 너무 많은 단어가 필요할 것이다.
Word 기반의 단어사전 구축이 가지는 문제점이다.
특히 한국어의 경우에는 이런 문제점이 심각할 것이다.
만약 '읽었다'를 '읽'+'었다'로 나누어서 처리할 수 있다면 어떨까❓❓❓
이런 접근법을 'Subword Segmentation'이라고 한다.
BERT에는 WordPiece 모델 사용이 일반적이지만, 이번에는 SentencePiece 모델을 이용해서 Subword 기반의 텍스트 전처리를 진행할 것이다.
구글에서 오픈소스로 제공하는 SentencePiece 모델은 파이썬에서 손쉽게 사용 가능하며, WordPiece 등 다른 모델들을 통합하여 제공하므로 최근 널리 사용되고 있다.
다만, 한국어의 경우에는 koNLPy 를 통해 사용할 수 있는 형태소 분석기가 이런 역할을 한다.
하지만 SentencePiece 같은 모델들은 언어마다 다른 문법 규칙을 활용하지 않고, 적절한 Subword 분절 규칙을 학습하거나, 혹은 자주 사용되는 구문을 하나의 단어로 묶어내는 등 통계적인 방법을 사용한다.
그래서 어떤 언어에든 보편적으로 적용 가능하다는 장점이 있다.
# vocab loading
vocab = spm.SentencePieceProcessor()
vocab.load(f"{model_dir}/ko_32000.model")
# word를 subword로 변경하면서 index 저장
word_to_token = []
context_tokens = []
for (i, word) in enumerate(word_tokens):
word_to_token.append(len(context_tokens))
tokens = vocab.encode_as_pieces(word) # SentencePiece를 사용해 Subword로 쪼갭니다.
for token in tokens:
context_tokens.append(token)
context_tokens, word_to_token(['▁1839', '년', '▁', '파우스트', '를', '▁읽', '었다', '.'], [0, 2, 5])위에서 '_읽'에는 '_'이 있고, '었다'에는 '_'가 없는 것이 눈에 띄시나요? '_' 표시는 앞부분이 공백이라는 뜻이다.
여기서 word_to_token의 [0, 2, 5]란 context_tokens에 쪼개져 담긴 0번, 2번, 5번 토큰인 '▁1839', '▁', '▁읽' 이 어절 단위의 첫 번째 토큰이 된다는 정보를 담아둔 것이다.
그러면 SentencePiece를 활용하는 위 코드도 아래와 같이 함수로 만들어 두면 유용할 것이다.
def _tokenize_vocab(vocab, context_words):
word_to_token = []
context_tokens = []
for (i, word) in enumerate(context_words):
word_to_token.append(len(context_tokens))
tokens = vocab.encode_as_pieces(word)
for token in tokens:
context_tokens.append(token)
return context_tokens, word_to_tokenprint(word_tokens) # 처리해야 할 word 단위 입력
context_tokens, word_to_token = _tokenize_vocab(vocab, word_tokens)
context_tokens, word_to_token # Subword 단위로 토큰화한 결과['1839년', '파우스트를', '읽었다.'](['▁1839', '년', '▁', '파우스트', '를', '▁읽', '었다', '.'], [0, 2, 5])KorQuAD 데이터셋 전처리 (3) Improve Span
KorQuAD 데이터셋에서 context, question, answer를 뽑아 봅니다. KorQuAD 데이터셋은 질문(question) 과 지문(context) 을 주고, 지문 영역에서 정답(answer) 을 찾도록 구성되어 있다.
그러므로 정답에 해당하는 지문 영역을 정확히 찾아내는 것이 전처리의 핵심적인 작업이 될 것이다.
context = train_json['data'][0]['paragraphs'][0]['context']
question = train_json['data'][0]['paragraphs'][0]['qas'][0]['question']
answer_text = train_json['data'][0]['paragraphs'][0]['qas'][0]['answers'][0]['text']
answer_start = train_json['data'][0]['paragraphs'][0]['qas'][0]['answers'][0]['answer_start']
answer_end = answer_start + len(answer_text) - 1
print('[context] ', context)
print('[question] ', question)
print('[answer] ', answer_text)
print('[answer_start] index: ', answer_start, 'character: ', context[answer_start])
print('[answer_end]index: ', answer_end, 'character: ', context[answer_end])
# answer_text에 해당하는 context 영역을 정확히 찾아내야 합니다.
assert context[answer_start:answer_end + 1] == answer_text[context] 1839년 바그너는 괴테의 파우스트을 처음 읽고 그 내용에 마음이 끌려 이를 소재로 해서 하나의 교향곡을 쓰려는 뜻을 갖는다. 이 시기 바그너는 1838년에 빛 독촉으로 산전수전을 다 걲은 상황이라 좌절과 실망에 가득했으며 메피스토펠레스를 만나는 파우스트의 심경에 공감했다고 한다. 또한 파리에서 아브네크의 지휘로 파리 음악원 관현악단이 연주하는 베토벤의 교향곡 9번을 듣고 깊은 감명을 받았는데, 이것이 이듬해 1월에 파우스트의 서곡으로 쓰여진 이 작품에 조금이라도 영향을 끼쳤으리라는 것은 의심할 여지가 없다. 여기의 라단조 조성의 경우에도 그의 전기에 적혀 있는 것처럼 단순한 정신적 피로나 실의가 반영된 것이 아니라 베토벤의 합창교향곡 조성의 영향을 받은 것을 볼 수 있다. 그렇게 교향곡 작곡을 1839년부터 40년에 걸쳐 파리에서 착수했으나 1악장을 쓴 뒤에 중단했다. 또한 작품의 완성과 동시에 그는 이 서곡(1악장)을 파리 음악원의 연주회에서 연주할 파트보까지 준비하였으나, 실제로는 이루어지지는 않았다. 결국 초연은 4년 반이 지난 후에 드레스덴에서 연주되었고 재연도 이루어졌지만, 이후에 그대로 방치되고 말았다. 그 사이에 그는 리엔치와 방황하는 네덜란드인을 완성하고 탄호이저에도 착수하는 등 분주한 시간을 보냈는데, 그런 바쁜 생활이 이 곡을 잊게 한 것이 아닌가 하는 의견도 있다.
[question] 바그너는 괴테의 파우스트를 읽고 무엇을 쓰고자 했는가?
[answer] 교향곡
[answer_start] index: 54 character: 교
[answer_end]index: 56 character: 곡# context를 띄어쓰기(word) 단위로 토큰화한 결과를 살펴봅니다.
word_tokens, char_to_word = _tokenize_whitespace(context)
print( word_tokens[:20])
char_to_word[:20], context[:20]['1839년', '바그너는', '괴테의', '파우스트을', '처음', '읽고', '그', '내용에', '마음이', '끌려', '이를', '소재로', '해서', '하나의', '교향곡을', '쓰려는', '뜻을', '갖는다.', '이', '시기']([0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3],
'1839년 바그너는 괴테의 파우스트을')# 띄어쓰기(word) 단위로 쪼개진 context(word_tokens)를 Subword로 토큰화한 결과를 살펴봅니다.
context_tokens, word_to_token = _tokenize_vocab(vocab, word_tokens)
for i in range(min(20, len(word_to_token) - 1)):
print(word_to_token[i], context_tokens[word_to_token[i]:word_to_token[i + 1]])0 ['▁1839', '년']
2 ['▁바그너', '는']
4 ['▁괴테', '의']
6 ['▁', '파우스트', '을']
9 ['▁처음']
10 ['▁읽고']
11 ['▁그']
12 ['▁내용에']
13 ['▁마음이']
14 ['▁끌려']
15 ['▁이를']
16 ['▁소재로']
17 ['▁해서']
18 ['▁하나의']
19 ['▁교향곡', '을']
21 ['▁쓰', '려는']
23 ['▁뜻을']
24 ['▁갖는다', '.']
26 ['▁이']
27 ['▁시기']이제 질문의 답을 떠올려 보자.
위에서 context에 포함된 answer의 글자 단위 시작 인덱스 answer_start 와 종료 인덱스 answer_end 를 구했다.
이 위치를 어절(word) 단위로 변환하면 어떻게 될까❓❓❓
# answer_start와 answer_end로부터 word_start와 word_end를 구합니다.
word_start = char_to_word[answer_start]
word_end = char_to_word[answer_end]
word_start, word_end, answer_text, word_tokens[word_start:word_end + 1](14, 14, '교향곡', ['교향곡을'])정답은 15번째 어절(index=14)에 있었군요. 하지만 우리가 원하는 정답은 '교향곡'이지, '교향곡을'은 아니다.
그래서 이번에는 word_start 로부터 word_end 까지의 context를 Subword 단위로 토큰화한 결과를 살펴보자.
token_start = word_to_token[word_start]
if word_end < len(word_to_token) - 1:
token_end = word_to_token[word_end + 1] - 1
else:
token_end = len(context_tokens) - 1
token_start, token_end, context_tokens[token_start:token_end + 1](19, 20, ['▁교향곡', '을'])이제 거의 정답에 근접하였다.
Subword 단위로 토큰화한 결과 중에는 우리가 찾는 정답과 정확히 일치하는 답이 있는 것 같다.
# 실제 정답인 answer_text도 Subword 기준으로 토큰화해 둡니다.
token_answer = " ".join(vocab.encode_as_pieces(answer_text))
token_answer
'▁교향곡'눈으로 봐도 어디가 정확히 정답인지 알 수 있게 되었지만, 좀 더 일반적인 방법으로 정답 토큰 범위를 찾는 코드를 작성해 보자.
KorQuAD 문제의 정답은 이번처럼 단답형만 있는 것은 아니기 때문이다.
# 정답이 될수 있는 new_start와 new_end의 경우를 순회탐색합니다.
for new_start in range(token_start, token_end + 1):
for new_end in range(token_end, new_start - 1, -1):
text_span = " ".join(context_tokens[new_start : (new_end + 1)])
if text_span == token_answer: # 정답과 일치하는 경우
print("O >>", (new_start, new_end), text_span)
else:
print("X >>", (new_start, new_end), text_span)X >> (19, 20) ▁교향곡 을
O >> (19, 19) ▁교향곡
X >> (20, 20) 을이제 context에서 answer의 위치를 토큰화 된 상태에서 찾는 함수를 아래와 같이 정리할 수 있게 되었다.
In [26]:
# context_tokens에서 char_answer의 위치를 찾아 리턴하는 함수
def _improve_span(vocab, context_tokens, token_start, token_end, char_answer):
token_answer = " ".join(vocab.encode_as_pieces(char_answer))
for new_start in range(token_start, token_end + 1):
for new_end in range(token_end, new_start - 1, -1):
text_span = " ".join(context_tokens[new_start : (new_end + 1)])
if text_span == token_answer:
return (new_start, new_end)
return (token_start, token_end)잘 작동하는지 확인해보자.
token_start, token_end = _improve_span(vocab, context_tokens, token_start, token_end, answer_text)
print('token_start:', token_start, ' token_end:', token_end)
context_tokens[token_start:token_end + 1]token_start: 19 token_end: 19['▁교향곡']KorQuAD 데이터셋 전처리 (4) 데이터셋 분리
train 데이터셋, dev 데이터셋을 분리하여, 위에서 작성한 _improve_span() 함수를 이용해 전처리 후 파일로 저장한다.
def dump_korquad(vocab, json_data, out_file):
with open(out_file, "w") as f:
for data in tqdm(json_data["data"]):
title = data["title"]
for paragraph in data["paragraphs"]:
context = paragraph["context"]
context_words, char_to_word = _tokenize_whitespace(context)
for qa in paragraph["qas"]:
assert len(qa["answers"]) == 1
qa_id = qa["id"]
question = qa["question"]
answer_text = qa["answers"][0]["text"]
answer_start = qa["answers"][0]["answer_start"]
answer_end = answer_start + len(answer_text) - 1
assert answer_text == context[answer_start:answer_end + 1]
word_start = char_to_word[answer_start]
word_end = char_to_word[answer_end]
word_answer = " ".join(context_words[word_start:word_end + 1])
char_answer = " ".join(answer_text.strip().split())
assert char_answer in word_answer
context_tokens, word_to_token = _tokenize_vocab(vocab, context_words)
token_start = word_to_token[word_start]
if word_end < len(word_to_token) - 1:
token_end = word_to_token[word_end + 1] - 1
else:
token_end = len(context_tokens) - 1
token_start, token_end = _improve_span(vocab, context_tokens, token_start, token_end, char_answer)
data = {"qa_id": qa_id, "title": title, "question": vocab.encode_as_pieces(question), "context": context_tokens, "answer": char_answer, "token_start": token_start, "token_end":token_end}
f.write(json.dumps(data, ensure_ascii=False))
f.write("\n")# 전처리를 수행하여 파일로 생성합니다.
dump_korquad(vocab, train_json, f"{data_dir}/korquad_train.json")
dump_korquad(vocab, dev_json, f"{data_dir}/korquad_dev.json")전처리가 의도대로 잘 되었는지 실제로 파일 내용을 확인해 보자.
def print_file(filename, count=10):
"""
파일 내용 출력
:param filename: 파일 이름
:param count: 출력 라인 수
"""
with open(filename) as f:
for i, line in enumerate(f):
if count <= i:
break
print(line.strip())
print_file(f"{data_dir}/korquad_train.json"){"qa_id": "6566495-0-0", "title": "파우스트_서곡", "question": ["▁바그너", "는", "▁괴테", "의", "▁", "파우스트", "를", "▁읽고", "▁무엇을", "▁쓰고", "자", "▁", "했", "는", "가", "?"], "context": ["▁1839", "년", "▁바그너", "는", "▁괴테", "의", "▁", "파우스트", "을", "▁처음", "▁읽고", "▁그", "▁내용에", "▁마음이", "▁끌려", "▁이를", "▁소재로", "▁해서", "▁하나의", "▁교향곡", "을", "▁쓰", "려는", "▁뜻을", "▁갖는다", ".", "▁이", "▁시기", "▁바그너", "는", "▁1838", "년에", "▁빛", "▁독", "촉", "으로", "▁산", "전", "수", "전을", "▁다", "▁", "걲", "은", "▁상황이", "라", "▁좌절", "과", "▁실망", "에", "▁가득", "했으며", "▁메", "피스", "토", "펠", "레스", "를", "▁만나는", "▁", "파우스트", "의", "▁심", "경에", "▁공감", "했다고", "▁한다", ".", "▁또한", "▁파리에서", "▁아브", "네", "크의", "▁지휘", "로", "▁파리", "▁음악원", "▁관현악단", "이", "▁연주하는", "▁베토벤", "의", "▁교향곡", "▁9", "번을", "▁듣고", "▁깊은", "▁감", "명을", "▁받았는데", ",", "▁이것이", "▁이듬해", "▁1", "월에", "▁", "파우스트", "의", "▁서", "곡으로", "▁쓰여진", "▁이", "▁작품에", "▁조금", "이라도", "▁영향을", "▁끼", "쳤", "으리라", "는", "▁것은", "▁의심", "할", "▁여지가", "▁없다", ".", "▁여기", "의", "▁라", "단", "조", "▁조성", "의", "▁경우에도", "▁그의", "▁전기", "에", "▁적혀", "▁있는", "▁것처럼", "▁단순한", "▁정신적", "▁피로", "나", "▁실", "의", "가", "▁반영", "된", "▁것이", "▁아니라", "▁베토벤", "의", "▁합창", "교", "향", "곡", "▁조성", "의", "▁영향을", "▁받은", "▁것을", "▁볼", "▁수", "▁있다", ".", "▁그렇게", "▁교향곡", "▁작곡", "을", "▁1839", "년부터", "▁40", "년에", "▁걸쳐", "▁파리에서", "▁착수", "했으나", "▁1", "악장", "을", "▁쓴", "▁뒤에", "▁중단", "했다", ".", "▁또한", "▁작품의", "▁완성", "과", "▁동시에", "▁그는", "▁이", "▁서", "곡", "(1", "악장", ")", "을", "▁파리", "▁음악원", "의", "▁연주회", "에서", "▁연주", "할", "▁파트", "보", "까지", "▁준비", "하였으나", ",", "▁실제로는", "▁이루어지지", "는", "▁않았다", ".", "▁결국", "▁초연", "은", "▁4", "년", "▁반", "이", "▁지난", "▁후에", "▁드레스덴", "에서", "▁연주", "되었고", "▁재", "연", "도", "▁이루어졌", "지만", ",", "▁이후에", "▁그대로", "▁방치", "되고", "▁말았다", ".", "▁그", "▁사이에", "▁그는", "▁리", "엔", "치", "와", "▁방", "황", "하는", "▁네덜란드", "인", "을", "▁완성", "하고", "▁탄", "호", "이", "저", "에도", "▁착수", "하는", "▁등", "▁분", "주", "한", "▁시간을", "▁보", "냈는데", ",", "▁그런", "▁바쁜", "▁생활", "이", "▁이", "▁곡을", "▁잊", "게", "▁한", "▁것이", "▁아닌", "가", "▁하는", "▁의견도", "▁있다", "."], "answer": "교향곡", "token_start": 19, "token_end": 19}
{"qa_id": "6566495-0-1", "title": "파우스트_서곡", "question": ["▁바그너", "는", "▁교향곡", "▁작곡", "을", "▁어디", "까지", "▁쓴", "▁뒤에", "▁중단", "했", "는", "가", "?"], "context": ["▁1839", "년", "▁바그너", "는", "▁괴테", "의", "▁", "파우스트", "을", "▁처음", "▁읽고", "▁그", "▁내용에", "▁마음이", "▁끌려", "▁이를", "▁소재로", "▁해서", "▁하나의", "▁교향곡", "을", "▁쓰", "려는", "▁뜻을", "▁갖는다", ".", "▁이", "▁시기", "▁바그너", "는", "▁1838", "년에", "▁빛", "▁독", "촉", "으로", "▁산", "전", "수", "전을", "▁다", "▁", "걲", "은", "▁상황이", "라", "▁좌절", "과", "▁실망", "에", "▁가득", "했으며", "▁메", "피스", "토", "펠", "레스", "를", "▁만나는", "▁", "파우스트", "의", "▁심", "경에", "▁공감", "했다고", "▁한다", ".", "▁또한", "▁파리에서", "▁아브", "네", "크의", "▁지휘", "로", "▁파리", "▁음악원", "▁관현악단", "이", "▁연주하는", "▁베토벤", "의", "▁교향곡", "▁9", "번을", "▁듣고", "▁깊은", "▁감", "명을", "▁받았는데", ",", "▁이것이", "▁이듬해", "▁1", "월에", "▁", "파우스트", "의", "▁서", "곡으로", "▁쓰여진", "▁이", "▁작품에", "▁조금", "이라도", "▁영향을", "▁끼", "쳤", "으리라", "는", "▁것은", "▁의심", "할", "▁여지가", "▁없다", ".", "▁여기", "의", "▁라", "단", "조", "▁조성", "의", "▁경우에도", "▁그의", "▁전기", "에", "▁적혀", "▁있는", "▁것처럼", "▁단순한", "▁정신적", "▁피로", "나", "▁실", "의", "가", "▁반영", "된", "▁것이", "▁아니라", "▁베토벤", "의", "▁합창", "교", "향", "곡", "▁조성", "의", "▁영향을", "▁받은", "▁것을", "▁볼", "▁수", "▁있다", ".", "▁그렇게", "▁교향곡", "▁작곡", "을", "▁1839", "년부터", "▁40", "년에", "▁걸쳐", "▁파리에서", "▁착수", "했으나", "▁1", "악장", "을", "▁쓴", "▁뒤에", "▁중단", "했다", ".", "▁또한", "▁작품의", "▁완성", "과", "▁동시에", "▁그는", "▁이", "▁서", "곡", "(1", "악장", ")", "을", "▁파리", "▁음악원", "의", "▁연주회", "에서", "▁연주", "할", "▁파트", "보", "까지", "▁준비", "하였으나", ",", "▁실제로는", "▁이루어지지", "는", "▁않았다", ".", "▁결국", "▁초연", "은", "▁4", "년", "▁반", "이", "▁지난", "▁후에", "▁드레스덴", "에서", "▁연주", "되었고", "▁재", "연", "도", "▁이루어졌", "지만", ",", "▁이후에", "▁그대로", "▁방치", "되고", "▁말았다", ".", "▁그", "▁사이에", "▁그는", "▁리", "엔", "치", "와", "▁방", "황", "하는", "▁네덜란드", "인", "을", "▁완성", "하고", "▁탄", "호", "이", "저", "에도", "▁착수", "하는", "▁등", "▁분", "주", "한", "▁시간을", "▁보", "냈는데", ",", "▁그런", "▁바쁜", "▁생활", "이", "▁이", "▁곡을", "▁잊", "게", "▁한", "▁것이", "▁아닌", "가", "▁하는", "▁의견도", "▁있다", "."], "answer": "1악장", "token_start": 168, "token_end": 169}
{"qa_id": "6566495-0-2", "title": "파우스트_서곡", "question": ["▁바그너", "가", "▁", "파우스트", "▁서", "곡을", "▁쓸", "▁때", "▁어떤", "▁곡", "의", "▁영향을", "▁받았", "는", "가", "?"], "context": ["▁1839", "년", "▁바그너", "는", "▁괴테", "의", "▁", "파우스트", "을", "▁처음", "▁읽고", "▁그", "▁내용에", "▁마음이", "▁끌려", "▁이를", "▁소재로", "▁해서", "▁하나의", "▁교향곡", "을", "▁쓰", "려는", "▁뜻을", "▁갖는다", ".", "▁이", "▁시기", "▁바그너", "는", "▁1838", "년에", "▁빛", "▁독", "촉", "으로", "▁산", "전", "수", "전을", "▁다", "▁", "걲", "은", "▁상황이", "라", "▁좌절", "과", "▁실망", "에", "▁가득", "했으며", "▁메", "피스", "토", "펠", "레스", "를", "▁만나는", "▁", "파우스트", "의", "▁심", "경에", "▁공감", "했다고", "▁한다", ".", "▁또한", "▁파리에서", "▁아브", "네", "크의", "▁지휘", "로", "▁파리", "▁음악원", "▁관현악단", "이", "▁연주하는", "▁베토벤", "의", "▁교향곡", "▁9", "번을", "▁듣고", "▁깊은", "▁감", "명을", "▁받았는데", ",", "▁이것이", "▁이듬해", "▁1", "월에", "▁", "파우스트", "의", "▁서", "곡으로", "▁쓰여진", "▁이", "▁작품에", "▁조금", "이라도", "▁영향을", "▁끼", "쳤", "으리라", "는", "▁것은", "▁의심", "할", "▁여지가", "▁없다", ".", "▁여기", "의", "▁라", "단", "조", "▁조성", "의", "▁경우에도", "▁그의", "▁전기", "에", "▁적혀", "▁있는", "▁것처럼", "▁단순한", "▁정신적", "▁피로", "나", "▁실", "의", "가", "▁반영", "된", "▁것이", "▁아니라", "▁베토벤", "의", "▁합창", "교", "향", "곡", "▁조성", "의", "▁영향을", "▁받은", "▁것을", "▁볼", "▁수", "▁있다", ".", "▁그렇게", "▁교향곡", "▁작곡", "을", "▁1839", "년부터", "▁40", "년에", "▁걸쳐", "▁파리에서", "▁착수", "했으나", "▁1", "악장", "을", "▁쓴", "▁뒤에", "▁중단", "했다", ".", "▁또한", "▁작품의", "▁완성", "과", "▁동시에", "▁그는", "▁이", "▁서", "곡", "(1", "악장", ")", "을", "▁파리", "▁음악원", "의", "▁연주회", "에서", "▁연주", "할", "▁파트", "보", "까지", "▁준비", "하였으나", ",", "▁실제로는", "▁이루어지지", "는", "▁않았다", ".", "▁결국", "▁초연", "은", "▁4", "년", "▁반", "이", "▁지난", "▁후에", "▁드레스덴", "에서", "▁연주", "되었고", "▁재", "연", "도", "▁이루어졌", "지만", ",", "▁이후에", "▁그대로", "▁방치", "되고", "▁말았다", ".", "▁그", "▁사이에", "▁그는", "▁리", "엔", "치", "와", "▁방", "황", "하는", "▁네덜란드", "인", "을", "▁완성", "하고", "▁탄", "호", "이", "저", "에도", "▁착수", "하는", "▁등", "▁분", "주", "한", "▁시간을", "▁보", "냈는데", ",", "▁그런", "▁바쁜", "▁생활", "이", "▁이", "▁곡을", "▁잊", "게", "▁한", "▁것이", "▁아닌", "가", "▁하는", "▁의견도", "▁있다", "."], "answer": "베토벤의 교향곡 9번", "token_start": 80, "token_end": 84}
{"qa_id": "6566518-0-0", "title": "파우스트_서곡", "question": ["▁1839", "년", "▁바그너", "가", "▁교향곡", "의", "▁소재로", "▁쓰", "려고", "▁했던", "▁책은", "?"], "context": ["▁1839", "년", "▁바그너", "는", "▁괴테", "의", "▁", "파우스트", "을", "▁처음", "▁읽고", "▁그", "▁내용에", "▁마음이", "▁끌려", "▁이를", "▁소재로", "▁해서", "▁하나의", "▁교향곡", "을", "▁쓰", "려는", "▁뜻을", "▁갖는다", ".", "▁이", "▁시기", "▁바그너", "는", "▁1838", "년에", "▁빛", "▁독", "촉", "으로", "▁산", "전", "수", "전을", "▁다", "▁", "걲", "은", "▁상황이", "라", "▁좌절", "과", "▁실망", "에", "▁가득", "했으며", "▁메", "피스", "토", "펠", "레스", "를", "▁만나는", "▁", "파우스트", "의", "▁심", "경에", "▁공감", "했다고", "▁한다", ".", "▁또한", "▁파리에서", "▁아브", "네", "크의", "▁지휘", "로", "▁파리", "▁음악원", "▁관현악단", "이", "▁연주하는", "▁베토벤", "의", "▁교향곡", "▁9", "번을", "▁듣고", "▁깊은", "▁감", "명을", "▁받았는데", ",", "▁이것이", "▁이듬해", "▁1", "월에", "▁", "파우스트", "의", "▁서", "곡으로", "▁쓰여진", "▁이", "▁작품에", "▁조금", "이라도", "▁영향을", "▁끼", "쳤", "으리라", "는", "▁것은", "▁의심", "할", "▁여지가", "▁없다", ".", "▁여기", "의", "▁라", "단", "조", "▁조성", "의", "▁경우에도", "▁그의", "▁전기", "에", "▁적혀", "▁있는", "▁것처럼", "▁단순한", "▁정신적", "▁피로", "나", "▁실", "의", "가", "▁반영", "된", "▁것이", "▁아니라", "▁베토벤", "의", "▁합창", "교", "향", "곡", "▁조성", "의", "▁영향을", "▁받은", "▁것을", "▁볼", "▁수", "▁있다", ".", "▁그렇게", "▁교향곡", "▁작곡", "을", "▁1839", "년부터", "▁40", "년에", "▁걸쳐", "▁파리에서", "▁착수", "했으나", "▁1", "악장", "을", "▁쓴", "▁뒤에", "▁중단", "했다", ".", "▁또한", "▁작품의", "▁완성", "과", "▁동시에", "▁그는", "▁이", "▁서", "곡", "(1", "악장", ")", "을", "▁파리", "▁음악원", "의", "▁연주회", "에서", "▁연주", "할", "▁파트", "보", "까지", "▁준비", "하였으나", ",", "▁실제로는", "▁이루어지지", "는", "▁않았다", ".", "▁결국", "▁초연", "은", "▁4", "년", "▁반", "이", "▁지난", "▁후에", "▁드레스덴", "에서", "▁연주", "되었고", "▁재", "연", "도", "▁이루어졌", "지만", ",", "▁이후에", "▁그대로", "▁방치", "되고", "▁말았다", ".", "▁그", "▁사이에", "▁그는", "▁리", "엔", "치", "와", "▁방", "황", "하는", "▁네덜란드", "인", "을", "▁완성", "하고", "▁탄", "호", "이", "저", "에도", "▁착수", "하는", "▁등", "▁분", "주", "한", "▁시간을", "▁보", "냈는데", ",", "▁그런", "▁바쁜", "▁생활", "이", "▁이", "▁곡을", "▁잊", "게", "▁한", "▁것이", "▁아닌", "가", "▁하는", "▁의견도", "▁있다", "."], "answer": "파우스트", "token_start": 6, "token_end": 7}
{"qa_id": "6566518-0-1", "title": "파우스트_서곡", "question": ["▁", "파우스트", "▁서", "곡", "의", "▁라", "단", "조", "▁조성", "이", "▁영향을", "▁받은", "▁베토벤", "의", "▁곡은", "?"], "context": ["▁1839", "년", "▁바그너", "는", "▁괴테", "의", "▁", "파우스트", "을", "▁처음", "▁읽고", "▁그", "▁내용에", "▁마음이", "▁끌려", "▁이를", "▁소재로", "▁해서", "▁하나의", "▁교향곡", "을", "▁쓰", "려는", "▁뜻을", "▁갖는다", ".", "▁이", "▁시기", "▁바그너", "는", "▁1838", "년에", "▁빛", "▁독", "촉", "으로", "▁산", "전", "수", "전을", "▁다", "▁", "걲", "은", "▁상황이", "라", "▁좌절", "과", "▁실망", "에", "▁가득", "했으며", "▁메", "피스", "토", "펠", "레스", "를", "▁만나는", "▁", "파우스트", "의", "▁심", "경에", "▁공감", "했다고", "▁한다", ".", "▁또한", "▁파리에서", "▁아브", "네", "크의", "▁지휘", "로", "▁파리", "▁음악원", "▁관현악단", "이", "▁연주하는", "▁베토벤", "의", "▁교향곡", "▁9", "번을", "▁듣고", "▁깊은", "▁감", "명을", "▁받았는데", ",", "▁이것이", "▁이듬해", "▁1", "월에", "▁", "파우스트", "의", "▁서", "곡으로", "▁쓰여진", "▁이", "▁작품에", "▁조금", "이라도", "▁영향을", "▁끼", "쳤", "으리라", "는", "▁것은", "▁의심", "할", "▁여지가", "▁없다", ".", "▁여기", "의", "▁라", "단", "조", "▁조성", "의", "▁경우에도", "▁그의", "▁전기", "에", "▁적혀", "▁있는", "▁것처럼", "▁단순한", "▁정신적", "▁피로", "나", "▁실", "의", "가", "▁반영", "된", "▁것이", "▁아니라", "▁베토벤", "의", "▁합창", "교", "향", "곡", "▁조성", "의", "▁영향을", "▁받은", "▁것을", "▁볼", "▁수", "▁있다", ".", "▁그렇게", "▁교향곡", "▁작곡", "을", "▁1839", "년부터", "▁40", "년에", "▁걸쳐", "▁파리에서", "▁착수", "했으나", "▁1", "악장", "을", "▁쓴", "▁뒤에", "▁중단", "했다", ".", "▁또한", "▁작품의", "▁완성", "과", "▁동시에", "▁그는", "▁이", "▁서", "곡", "(1", "악장", ")", "을", "▁파리", "▁음악원", "의", "▁연주회", "에서", "▁연주", "할", "▁파트", "보", "까지", "▁준비", "하였으나", ",", "▁실제로는", "▁이루어지지", "는", "▁않았다", ".", "▁결국", "▁초연", "은", "▁4", "년", "▁반", "이", "▁지난", "▁후에", "▁드레스덴", "에서", "▁연주", "되었고", "▁재", "연", "도", "▁이루어졌", "지만", ",", "▁이후에", "▁그대로", "▁방치", "되고", "▁말았다", ".", "▁그", "▁사이에", "▁그는", "▁리", "엔", "치", "와", "▁방", "황", "하는", "▁네덜란드", "인", "을", "▁완성", "하고", "▁탄", "호", "이", "저", "에도", "▁착수", "하는", "▁등", "▁분", "주", "한", "▁시간을", "▁보", "냈는데", ",", "▁그런", "▁바쁜", "▁생활", "이", "▁이", "▁곡을", "▁잊", "게", "▁한", "▁것이", "▁아닌", "가", "▁하는", "▁의견도", "▁있다", "."], "answer": "합창교향곡", "token_start": 143, "token_end": 146}
{"qa_id": "5917067-0-0", "title": "파우스트_서곡", "question": ["▁바그너", "가", "▁", "파우스트", "를", "▁처음으로", "▁읽", "은", "▁", "년", "도", "는", "?"], "context": ["▁1839", "년", "▁바그너", "는", "▁괴테", "의", "▁", "파우스트", "을", "▁처음", "▁읽고", "▁그", "▁내용에", "▁마음이", "▁끌려", "▁이를", "▁소재로", "▁해서", "▁하나의", "▁교향곡", "을", "▁쓰", "려는", "▁뜻을", "▁갖는다", ".", "▁이", "▁시기", "▁바그너", "는", "▁1838", "년에", "▁빛", "▁독", "촉", "으로", "▁산", "전", "수", "전을", "▁다", "▁", "걲", "은", "▁상황이", "라", "▁좌절", "과", "▁실망", "에", "▁가득", "했으며", "▁메", "피스", "토", "펠", "레스", "를", "▁만나는", "▁", "파우스트", "의", "▁심", "경에", "▁공감", "했다고", "▁한다", ".", "▁또한", "▁파리에서", "▁아브", "네", "크의", "▁지휘", "로", "▁파리", "▁음악원", "▁관현악단", "이", "▁연주하는", "▁베토벤", "의", "▁교향곡", "▁9", "번을", "▁듣고", "▁깊은", "▁감", "명을", "▁받았는데", ",", "▁이것이", "▁이듬해", "▁1", "월에", "▁", "파우스트", "의", "▁서", "곡으로", "▁쓰여진", "▁이", "▁작품에", "▁조금", "이라도", "▁영향을", "▁끼", "쳤", "으리라", "는", "▁것은", "▁의심", "할", "▁여지가", "▁없다", ".", "▁여기", "의", "▁라", "단", "조", "▁조성", "의", "▁경우에도", "▁그의", "▁전기", "에", "▁적혀", "▁있는", "▁것처럼", "▁단순한", "▁정신적", "▁피로", "나", "▁실", "의", "가", "▁반영", "된", "▁것이", "▁아니라", "▁베토벤", "의", "▁합창", "교", "향", "곡", "▁조성", "의", "▁영향을", "▁받은", "▁것을", "▁볼", "▁수", "▁있다", ".", "▁그렇게", "▁교향곡", "▁작곡", "을", "▁1839", "년부터", "▁40", "년에", "▁걸쳐", "▁파리에서", "▁착수", "했으나", "▁1", "악장", "을", "▁쓴", "▁뒤에", "▁중단", "했다", ".", "▁또한", "▁작품의", "▁완성", "과", "▁동시에", "▁그는", "▁이", "▁서", "곡", "(1", "악장", ")", "을", "▁파리", "▁음악원", "의", "▁연주회", "에서", "▁연주", "할", "▁파트", "보", "까지", "▁준비", "하였으나", ",", "▁실제로는", "▁이루어지지", "는", "▁않았다", ".", "▁결국", "▁초연", "은", "▁4", "년", "▁반", "이", "▁지난", "▁후에", "▁드레스덴", "에서", "▁연주", "되었고", "▁재", "연", "도", "▁이루어졌", "지만", ",", "▁이후에", "▁그대로", "▁방치", "되고", "▁말았다", ".", "▁그", "▁사이에", "▁그는", "▁리", "엔", "치", "와", "▁방", "황", "하는", "▁네덜란드", "인", "을", "▁완성", "하고", "▁탄", "호", "이", "저", "에도", "▁착수", "하는", "▁등", "▁분", "주", "한", "▁시간을", "▁보", "냈는데", ",", "▁그런", "▁바쁜", "▁생활", "이", "▁이", "▁곡을", "▁잊", "게", "▁한", "▁것이", "▁아닌", "가", "▁하는", "▁의견도", "▁있다", "."], "answer": "1839", "token_start": 0, "token_end": 0}
{"qa_id": "5917067-0-1", "title": "파우스트_서곡", "question": ["▁바그너", "가", "▁처음", "▁교향곡", "▁작곡", "을", "▁한", "▁장소", "는", "?"], "context": ["▁1839", "년", "▁바그너", "는", "▁괴테", "의", "▁", "파우스트", "을", "▁처음", "▁읽고", "▁그", "▁내용에", "▁마음이", "▁끌려", "▁이를", "▁소재로", "▁해서", "▁하나의", "▁교향곡", "을", "▁쓰", "려는", "▁뜻을", "▁갖는다", ".", "▁이", "▁시기", "▁바그너", "는", "▁1838", "년에", "▁빛", "▁독", "촉", "으로", "▁산", "전", "수", "전을", "▁다", "▁", "걲", "은", "▁상황이", "라", "▁좌절", "과", "▁실망", "에", "▁가득", "했으며", "▁메", "피스", "토", "펠", "레스", "를", "▁만나는", "▁", "파우스트", "의", "▁심", "경에", "▁공감", "했다고", "▁한다", ".", "▁또한", "▁파리에서", "▁아브", "네", "크의", "▁지휘", "로", "▁파리", "▁음악원", "▁관현악단", "이", "▁연주하는", "▁베토벤", "의", "▁교향곡", "▁9", "번을", "▁듣고", "▁깊은", "▁감", "명을", "▁받았는데", ",", "▁이것이", "▁이듬해", "▁1", "월에", "▁", "파우스트", "의", "▁서", "곡으로", "▁쓰여진", "▁이", "▁작품에", "▁조금", "이라도", "▁영향을", "▁끼", "쳤", "으리라", "는", "▁것은", "▁의심", "할", "▁여지가", "▁없다", ".", "▁여기", "의", "▁라", "단", "조", "▁조성", "의", "▁경우에도", "▁그의", "▁전기", "에", "▁적혀", "▁있는", "▁것처럼", "▁단순한", "▁정신적", "▁피로", "나", "▁실", "의", "가", "▁반영", "된", "▁것이", "▁아니라", "▁베토벤", "의", "▁합창", "교", "향", "곡", "▁조성", "의", "▁영향을", "▁받은", "▁것을", "▁볼", "▁수", "▁있다", ".", "▁그렇게", "▁교향곡", "▁작곡", "을", "▁1839", "년부터", "▁40", "년에", "▁걸쳐", "▁파리에서", "▁착수", "했으나", "▁1", "악장", "을", "▁쓴", "▁뒤에", "▁중단", "했다", ".", "▁또한", "▁작품의", "▁완성", "과", "▁동시에", "▁그는", "▁이", "▁서", "곡", "(1", "악장", ")", "을", "▁파리", "▁음악원", "의", "▁연주회", "에서", "▁연주", "할", "▁파트", "보", "까지", "▁준비", "하였으나", ",", "▁실제로는", "▁이루어지지", "는", "▁않았다", ".", "▁결국", "▁초연", "은", "▁4", "년", "▁반", "이", "▁지난", "▁후에", "▁드레스덴", "에서", "▁연주", "되었고", "▁재", "연", "도", "▁이루어졌", "지만", ",", "▁이후에", "▁그대로", "▁방치", "되고", "▁말았다", ".", "▁그", "▁사이에", "▁그는", "▁리", "엔", "치", "와", "▁방", "황", "하는", "▁네덜란드", "인", "을", "▁완성", "하고", "▁탄", "호", "이", "저", "에도", "▁착수", "하는", "▁등", "▁분", "주", "한", "▁시간을", "▁보", "냈는데", ",", "▁그런", "▁바쁜", "▁생활", "이", "▁이", "▁곡을", "▁잊", "게", "▁한", "▁것이", "▁아닌", "가", "▁하는", "▁의견도", "▁있다", "."], "answer": "파리", "token_start": 165, "token_end": 165}
{"qa_id": "5917067-0-2", "title": "파우스트_서곡", "question": ["▁바그너", "의", "▁1", "악장", "의", "▁초연", "은", "▁어디서", "▁연주", "되었", "는", "가", "?"], "context": ["▁1839", "년", "▁바그너", "는", "▁괴테", "의", "▁", "파우스트", "을", "▁처음", "▁읽고", "▁그", "▁내용에", "▁마음이", "▁끌려", "▁이를", "▁소재로", "▁해서", "▁하나의", "▁교향곡", "을", "▁쓰", "려는", "▁뜻을", "▁갖는다", ".", "▁이", "▁시기", "▁바그너", "는", "▁1838", "년에", "▁빛", "▁독", "촉", "으로", "▁산", "전", "수", "전을", "▁다", "▁", "걲", "은", "▁상황이", "라", "▁좌절", "과", "▁실망", "에", "▁가득", "했으며", "▁메", "피스", "토", "펠", "레스", "를", "▁만나는", "▁", "파우스트", "의", "▁심", "경에", "▁공감", "했다고", "▁한다", ".", "▁또한", "▁파리에서", "▁아브", "네", "크의", "▁지휘", "로", "▁파리", "▁음악원", "▁관현악단", "이", "▁연주하는", "▁베토벤", "의", "▁교향곡", "▁9", "번을", "▁듣고", "▁깊은", "▁감", "명을", "▁받았는데", ",", "▁이것이", "▁이듬해", "▁1", "월에", "▁", "파우스트", "의", "▁서", "곡으로", "▁쓰여진", "▁이", "▁작품에", "▁조금", "이라도", "▁영향을", "▁끼", "쳤", "으리라", "는", "▁것은", "▁의심", "할", "▁여지가", "▁없다", ".", "▁여기", "의", "▁라", "단", "조", "▁조성", "의", "▁경우에도", "▁그의", "▁전기", "에", "▁적혀", "▁있는", "▁것처럼", "▁단순한", "▁정신적", "▁피로", "나", "▁실", "의", "가", "▁반영", "된", "▁것이", "▁아니라", "▁베토벤", "의", "▁합창", "교", "향", "곡", "▁조성", "의", "▁영향을", "▁받은", "▁것을", "▁볼", "▁수", "▁있다", ".", "▁그렇게", "▁교향곡", "▁작곡", "을", "▁1839", "년부터", "▁40", "년에", "▁걸쳐", "▁파리에서", "▁착수", "했으나", "▁1", "악장", "을", "▁쓴", "▁뒤에", "▁중단", "했다", ".", "▁또한", "▁작품의", "▁완성", "과", "▁동시에", "▁그는", "▁이", "▁서", "곡", "(1", "악장", ")", "을", "▁파리", "▁음악원", "의", "▁연주회", "에서", "▁연주", "할", "▁파트", "보", "까지", "▁준비", "하였으나", ",", "▁실제로는", "▁이루어지지", "는", "▁않았다", ".", "▁결국", "▁초연", "은", "▁4", "년", "▁반", "이", "▁지난", "▁후에", "▁드레스덴", "에서", "▁연주", "되었고", "▁재", "연", "도", "▁이루어졌", "지만", ",", "▁이후에", "▁그대로", "▁방치", "되고", "▁말았다", ".", "▁그", "▁사이에", "▁그는", "▁리", "엔", "치", "와", "▁방", "황", "하는", "▁네덜란드", "인", "을", "▁완성", "하고", "▁탄", "호", "이", "저", "에도", "▁착수", "하는", "▁등", "▁분", "주", "한", "▁시간을", "▁보", "냈는데", ",", "▁그런", "▁바쁜", "▁생활", "이", "▁이", "▁곡을", "▁잊", "게", "▁한", "▁것이", "▁아닌", "가", "▁하는", "▁의견도", "▁있다", "."], "answer": "드레스덴", "token_start": 216, "token_end": 216}
{"qa_id": "6566495-1-0", "title": "파우스트_서곡", "question": ["▁바그너", "의", "▁작품을", "▁시인", "의", "▁피로", "▁쓰여", "졌다", "고", "▁극찬", "한", "▁것은", "▁누구", "인", "가", "?"], "context": ["▁한편", "▁1840", "년부터", "▁바그너", "와", "▁알고", "▁지내던", "▁리스트", "가", "▁잊", "혀", "져", "▁있던", "▁1", "악장", "을", "▁부활", "시켜", "▁1852", "년에", "▁바이마르", "에서", "▁연주", "했다", ".", "▁이것을", "▁계기로", "▁바그너", "도", "▁이", "▁작품에", "▁다시", "▁관심을", "▁갖게", "▁되었고", ",", "▁그", "▁해", "▁9", "월에는", "▁총", "보", "의", "▁반환", "을", "▁요구", "하여", "▁이를", "▁서", "곡으로", "▁간", "추", "린", "▁다음", "▁수정", "을", "▁했고", "▁브", "라이트", "코프", "흐", "▁&", "▁헤르", "텔", "▁출판사", "에서", "▁출판", "할", "▁개정", "판", "도", "▁준비", "했다", ".", "▁1853", "년", "▁5", "월에는", "▁리스트", "가", "▁이", "▁작품이", "▁수정", "되었다", "는", "▁것을", "▁인정", "했지만", ",", "▁끝내", "▁바그너", "의", "▁출판", "▁계획은", "▁무산", "되고", "▁말았다", ".", "▁이후", "▁1855", "년에", "▁리스트", "가", "▁자신의", "▁작품", "▁", "파우스트", "▁교향곡", "을", "▁거의", "▁완성", "하여", "▁그", "▁사실을", "▁바그너", "에게", "▁알", "렸고", ",", "▁바그너", "는", "▁다시", "▁개정된", "▁총", "보를", "▁리스트", "에게", "▁보내고", "▁브", "라이트", "코프", "흐", "▁&", "▁헤르", "텔", "▁출판사", "에는", "▁20", "루이", "의", "▁금", "을", "▁받고", "▁팔았다", ".", "▁또한", "▁그의", "▁작품을", "▁“", "하나", "하나", "의", "▁음", "표", "가", "▁시인", "의", "▁피로", "▁쓰여", "졌다", "”", "며", "▁극찬", "했던", "▁한스", "▁폰", "▁", "뷜", "로", "가", "▁그것을", "▁피아노", "▁독주", "용으로", "▁편곡", "했는데", ",", "▁리스트", "는", "▁그것을", "▁약간", "▁변형", "되었을", "▁뿐", "이라고", "▁지적했다", ".", "▁이", "▁서", "곡", "의", "▁총", "보", "▁첫", "머리", "에는", "▁", "파우스트", "▁1", "부의", "▁내용", "▁중", "▁한", "▁구절", "을", "▁인용", "하고", "▁있다", "."], "answer": "한스 폰 뷜로", "token_start": 164, "token_end": 168}
{"qa_id": "6566495-1-1", "title": "파우스트_서곡", "question": ["▁잊", "혀", "져", "▁있는", "▁", "파우스트", "▁서", "곡", "▁1", "악장", "을", "▁부활", "시킨", "▁것은", "▁누구", "인", "가", "?"], "context": ["▁한편", "▁1840", "년부터", "▁바그너", "와", "▁알고", "▁지내던", "▁리스트", "가", "▁잊", "혀", "져", "▁있던", "▁1", "악장", "을", "▁부활", "시켜", "▁1852", "년에", "▁바이마르", "에서", "▁연주", "했다", ".", "▁이것을", "▁계기로", "▁바그너", "도", "▁이", "▁작품에", "▁다시", "▁관심을", "▁갖게", "▁되었고", ",", "▁그", "▁해", "▁9", "월에는", "▁총", "보", "의", "▁반환", "을", "▁요구", "하여", "▁이를", "▁서", "곡으로", "▁간", "추", "린", "▁다음", "▁수정", "을", "▁했고", "▁브", "라이트", "코프", "흐", "▁&", "▁헤르", "텔", "▁출판사", "에서", "▁출판", "할", "▁개정", "판", "도", "▁준비", "했다", ".", "▁1853", "년", "▁5", "월에는", "▁리스트", "가", "▁이", "▁작품이", "▁수정", "되었다", "는", "▁것을", "▁인정", "했지만", ",", "▁끝내", "▁바그너", "의", "▁출판", "▁계획은", "▁무산", "되고", "▁말았다", ".", "▁이후", "▁1855", "년에", "▁리스트", "가", "▁자신의", "▁작품", "▁", "파우스트", "▁교향곡", "을", "▁거의", "▁완성", "하여", "▁그", "▁사실을", "▁바그너", "에게", "▁알", "렸고", ",", "▁바그너", "는", "▁다시", "▁개정된", "▁총", "보를", "▁리스트", "에게", "▁보내고", "▁브", "라이트", "코프", "흐", "▁&", "▁헤르", "텔", "▁출판사", "에는", "▁20", "루이", "의", "▁금", "을", "▁받고", "▁팔았다", ".", "▁또한", "▁그의", "▁작품을", "▁“", "하나", "하나", "의", "▁음", "표", "가", "▁시인", "의", "▁피로", "▁쓰여", "졌다", "”", "며", "▁극찬", "했던", "▁한스", "▁폰", "▁", "뷜", "로", "가", "▁그것을", "▁피아노", "▁독주", "용으로", "▁편곡", "했는데", ",", "▁리스트", "는", "▁그것을", "▁약간", "▁변형", "되었을", "▁뿐", "이라고", "▁지적했다", ".", "▁이", "▁서", "곡", "의", "▁총", "보", "▁첫", "머리", "에는", "▁", "파우스트", "▁1", "부의", "▁내용", "▁중", "▁한", "▁구절", "을", "▁인용", "하고", "▁있다", "."], "answer": "리스트", "token_start": 7, "token_end": 7}KorQuAD 데이터셋 전처리 (5) 데이터 분석 : Question
원본 데이터셋을 전 처리하여 우리의 모델이 다루게 될 데이터셋으로 가공하는 과정을 진행하였다.
그러나 이 데이터셋을 그대로 사용할 수 있을지, 혹은 이상(abnormal) 데이터가 존재하지는 않는지 분석하는 과정이 필요하다.
우선 전체 데이터에서 question 항목의 길이 분포를 조사해 보자.
questions = []
contexts = []
token_starts = []
with open(f"{data_dir}/korquad_train.json") as f:
for i, line in enumerate(f):
data = json.loads(line)
questions.append(data["question"])
contexts.append(data["context"])
token_starts.append(data["token_start"])
if i < 10:
print(data["token_start"], data["question"])19 ['▁바그너', '는', '▁괴테', '의', '▁', '파우스트', '를', '▁읽고', '▁무엇을', '▁쓰고', '자', '▁', '했', '는', '가', '?']
168 ['▁바그너', '는', '▁교향곡', '▁작곡', '을', '▁어디', '까지', '▁쓴', '▁뒤에', '▁중단', '했', '는', '가', '?']
80 ['▁바그너', '가', '▁', '파우스트', '▁서', '곡을', '▁쓸', '▁때', '▁어떤', '▁곡', '의', '▁영향을', '▁받았', '는', '가', '?']
6 ['▁1839', '년', '▁바그너', '가', '▁교향곡', '의', '▁소재로', '▁쓰', '려고', '▁했던', '▁책은', '?']
143 ['▁', '파우스트', '▁서', '곡', '의', '▁라', '단', '조', '▁조성', '이', '▁영향을', '▁받은', '▁베토벤', '의', '▁곡은', '?']
0 ['▁바그너', '가', '▁', '파우스트', '를', '▁처음으로', '▁읽', '은', '▁', '년', '도', '는', '?']
165 ['▁바그너', '가', '▁처음', '▁교향곡', '▁작곡', '을', '▁한', '▁장소', '는', '?']
216 ['▁바그너', '의', '▁1', '악장', '의', '▁초연', '은', '▁어디서', '▁연주', '되었', '는', '가', '?']
164 ['▁바그너', '의', '▁작품을', '▁시인', '의', '▁피로', '▁쓰여', '졌다', '고', '▁극찬', '한', '▁것은', '▁누구', '인', '가', '?']
7 ['▁잊', '혀', '져', '▁있는', '▁', '파우스트', '▁서', '곡', '▁1', '악장', '을', '▁부활', '시킨', '▁것은', '▁누구', '인', '가', '?']# token count
train_question_counts = [len(question) for question in questions]
train_question_counts[:10][16, 14, 16, 12, 16, 13, 10, 13, 16, 18]# 그래프에 대한 이미지 사이즈 선언
# figsize: (가로, 세로) 형태의 튜플로 입력
plt.figure(figsize=(8, 4))
# histogram 선언
# bins: 히스토그램 값들에 대한 버켓 범위,
# range: x축 값의 범위
# facecolor: 그래프 색상
# label: 그래프에 대한 라벨
plt.hist(train_question_counts, bins=100, range=[0, 100], facecolor='b', label='train')
# 그래프 제목
plt.title('Count of question')
# 그래프 x 축 라벨
plt.xlabel('Number of question')
# 그래프 y 축 라벨
plt.ylabel('Count of question')
plt.show()
# 데이터 길이
print(f"question 길이 최대: {np.max(train_question_counts):4d}")
print(f"question 길이 최소: {np.min(train_question_counts):4d}")
print(f"question 길이 평균: {np.mean(train_question_counts):7.2f}")
print(f"question 길이 표준편차: {np.std(train_question_counts):7.2f}")
# https://ko.wikipedia.org/wiki/%EB%B0%B1%EB%B6%84%EC%9C%84%EC%88%98
# 백분위수(Percentile)는 크기가 있는 값들로 이뤄진 자료를 순서대로 나열했을 때 백분율로 나타낸 특정 위치의 값을 이르는 용어이다.
# 일반적으로 크기가 작은 것부터 나열하여 가장 작은 것을 0, 가장 큰 것을 100으로 한다.
# 100개의 값을 가진 어떤 자료의 20 백분위수는 그 자료의 값들 중 20번째로 작은 값을 뜻한다. 50 백분위수는 중앙값과 같다.
percentile25 = np.percentile(train_question_counts, 25)
percentile50 = np.percentile(train_question_counts, 50)
percentile75 = np.percentile(train_question_counts, 75)
percentileIQR = percentile75 - percentile25
percentileMAX = percentile75 + percentileIQR * 1.5
print(f"question 25/100분위: {percentile25:7.2f}")
print(f"question 50/100분위: {percentile50:7.2f}")
print(f"question 75/100분위: {percentile75:7.2f}")
print(f"question IQR: {percentileIQR:7.2f}")
print(f"question MAX/100분위: {percentileMAX:7.2f}")question 길이 최대: 58
question 길이 최소: 3
question 길이 평균: 15.25
question 길이 표준편차: 5.50
question 25/100분위: 11.00
question 50/100분위: 14.00
question 75/100분위: 18.00
question IQR: 7.00
question MAX/100분위: 28.50plt.figure(figsize=(4, 6))
# 박스플롯 생성
# 첫번째 파라메터: 여러 분포에 대한 데이터 리스트를
# labels: 입력한 데이터에 대한 라벨
# showmeans: 평균값을 표현
# 참고: https://leebaro.tistory.com/entry/%EB%B0%95%EC%8A%A4-%ED%94%8C%EB%A1%AFbox-plot-%EC%84%A4%EB%AA%85
plt.boxplot(train_question_counts, labels=['token counts'], showmeans=True)
plt.show()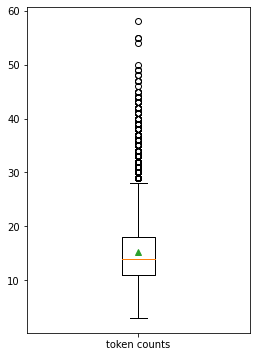
KorQuaD 데이터셋 전처리 (6) 데이터 분석 : Context
위와 동일한 방법으로 context 항목에 대해서도 분석해 보자.
# token count
train_context_counts = [len(context) for context in contexts]
train_context_counts[:10][278, 278, 278, 278, 278, 278, 278, 278, 209, 209]# 그래프에 대한 이미지 사이즈 선언
# figsize: (가로, 세로) 형태의 튜플로 입력
plt.figure(figsize=(8, 4))
# histogram 선언
# bins: 히스토그램 값들에 대한 버켓 범위,
# range: x축 값의 범위
# facecolor: 그래프 색상
# label: 그래프에 대한 라벨
plt.hist(train_context_counts, bins=900, range=[100, 1000], facecolor='r', label='train')
# 그래프 제목
plt.title('Count of context')
# 그래프 x 축 라벨
plt.xlabel('Number of context')
# 그래프 y 축 라벨
plt.ylabel('Count of context')
plt.show()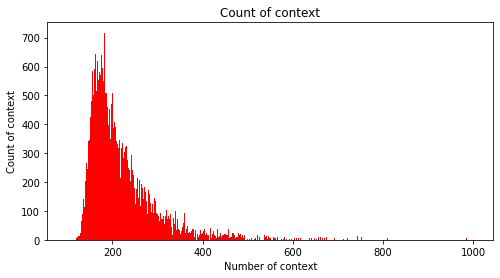
# 데이터 길이
print(f"context 길이 최대: {np.max(train_context_counts):4d}")
print(f"context 길이 최소: {np.min(train_context_counts):4d}")
print(f"context 길이 평균: {np.mean(train_context_counts):7.2f}")
print(f"context 길이 표준편차: {np.std(train_context_counts):7.2f}")
# https://ko.wikipedia.org/wiki/%EB%B0%B1%EB%B6%84%EC%9C%84%EC%88%98
# 백분위수(Percentile)는 크기가 있는 값들로 이뤄진 자료를 순서대로 나열했을 때 백분율로 나타낸 특정 위치의 값을 이르는 용어이다.
# 일반적으로 크기가 작은 것부터 나열하여 가장 작은 것을 0, 가장 큰 것을 100으로 한다.
# 100개의 값을 가진 어떤 자료의 20 백분위수는 그 자료의 값들 중 20번째로 작은 값을 뜻한다. 50 백분위수는 중앙값과 같다.
percentile25 = np.percentile(train_context_counts, 25)
percentile50 = np.percentile(train_context_counts, 50)
percentile75 = np.percentile(train_context_counts, 75)
percentileIQR = percentile75 - percentile25
percentileMAX = percentile75 + percentileIQR * 1.5
print(f"context 25/100분위: {percentile25:7.2f}")
print(f"context 50/100분위: {percentile50:7.2f}")
print(f"context 75/100분위: {percentile75:7.2f}")
print(f"context IQR: {percentileIQR:7.2f}")
print(f"context MAX/100분위: {percentileMAX:7.2f}")context 길이 최대: 4816
context 길이 최소: 108
context 길이 평균: 222.84
context 길이 표준편차: 97.68
context 25/100분위: 169.00
context 50/100분위: 199.00
context 75/100분위: 248.00
context IQR: 79.00
context MAX/100분위: 366.50plt.figure(figsize=(4, 6))
# 박스플롯 생성
# 첫번째 파라메터: 여러 분포에 대한 데이터 리스트를
# labels: 입력한 데이터에 대한 라벨
# showmeans: 평균값을 표현
# 참고: https://leebaro.tistory.com/entry/%EB%B0%95%EC%8A%A4-%ED%94%8C%EB%A1%AFbox-plot-%EC%84%A4%EB%AA%85
plt.boxplot(train_context_counts, labels=['token counts'], showmeans=True)
plt.show()
KorQuAD 데이터셋 전처리 (7) 데이터 분석 : Answer
위와 동일한 방법으로 answer 항목에 대해서도 분석해 보자.
# token count
train_answer_starts = token_starts
train_answer_starts[:10][19, 168, 80, 6, 143, 0, 165, 216, 164, 7]# 그래프에 대한 이미지 사이즈 선언
# figsize: (가로, 세로) 형태의 튜플로 입력
plt.figure(figsize=(8, 4))
# histogram 선언
# bins: 히스토그램 값들에 대한 버켓 범위,
# range: x축 값의 범위
# facecolor: 그래프 색상
# label: 그래프에 대한 라벨
plt.hist(train_answer_starts, bins=500, range=[0, 500], facecolor='g', label='train')
# 그래프 제목
plt.title('Count of answer')
# 그래프 x 축 라벨
plt.xlabel('Number of answer')
# 그래프 y 축 라벨
plt.ylabel('Count of answer')
plt.show()
# 데이터 길이
print(f"answer 위치 최대: {np.max(train_answer_starts):4d}")
print(f"answer 위치 최소: {np.min(train_answer_starts):4d}")
print(f"answer 위치 평균: {np.mean(train_answer_starts):7.2f}")
print(f"answer 위치 표준편차: {np.std(train_answer_starts):7.2f}")
# https://ko.wikipedia.org/wiki/%EB%B0%B1%EB%B6%84%EC%9C%84%EC%88%98
# 백분위수(Percentile)는 크기가 있는 값들로 이뤄진 자료를 순서대로 나열했을 때 백분율로 나타낸 특정 위치의 값을 이르는 용어이다.
# 일반적으로 크기가 작은 것부터 나열하여 가장 작은 것을 0, 가장 큰 것을 100으로 한다.
# 100개의 값을 가진 어떤 자료의 20 백분위수는 그 자료의 값들 중 20번째로 작은 값을 뜻한다. 50 백분위수는 중앙값과 같다.
percentile25 = np.percentile(train_answer_starts, 25)
percentile50 = np.percentile(train_answer_starts, 50)
percentile75 = np.percentile(train_answer_starts, 75)
percentileIQR = percentile75 - percentile25
percentileMAX = percentile75 + percentileIQR * 1.5
print(f"answer 25/100분위: {percentile25:7.2f}")
print(f"answer 50/100분위: {percentile50:7.2f}")
print(f"answer 75/100분위: {percentile75:7.2f}")
print(f"answer IQR: {percentileIQR:7.2f}")
print(f"answer MAX/100분위: {percentileMAX:7.2f}")answer 위치 최대: 1124
answer 위치 최소: 0
answer 위치 평균: 89.01
answer 위치 표준편차: 78.21
answer 25/100분위: 25.00
answer 50/100분위: 74.00
answer 75/100분위: 134.00
answer IQR: 109.00
answer MAX/100분위: 297.50plt.figure(figsize=(4, 6))
# 박스플롯 생성
# 첫번째 파라메터: 여러 분포에 대한 데이터 리스트를
# labels: 입력한 데이터에 대한 라벨
# showmeans: 평균값을 표현
# 참고: https://leebaro.tistory.com/entry/%EB%B0%95%EC%8A%A4-%ED%94%8C%EB%A1%AFbox-plot-%EC%84%A4%EB%AA%85
plt.boxplot(train_answer_starts, labels=['token counts'], showmeans=True)
plt.show()
KorQuAD 데이터셋 전처리 (8) 데이터 분석 : Word Cloud
워드 클라우드(Word Cloud)란 자료의 빈도수를 시각화해서 나타내는 방법이다.
문서의 핵심 단어를 한눈에 파악할 수 있고, 빅데이터를 분석할 때 데이터의 특징을 도출하기 위해서 활용된다
빈도수가 높은 단어일수록 글씨 크기가 큰 특징이 있다.
아래 코드를 실행 시켜 워드 클라우드를 확인해 보자.
# train documents
documents = []
# 전체 데이터에서 title, context, question 문장을 모두 추출합니다.
for data in tqdm(train_json["data"]):
title = data["title"]
documents.append(title)
for paragraph in data["paragraphs"]:
context = paragraph["context"]
documents.append(context)
for qa in paragraph["qas"]:
assert len(qa["answers"]) == 1
question = qa["question"]
documents.append(question)
documents[:10] # 그중 맨 앞 10개만 확인해 봅니다.['파우스트_서곡',
'1839년 바그너는 괴테의 파우스트을 처음 읽고 그 내용에 마음이 끌려 이를 소재로 해서 하나의 교향곡을 쓰려는 뜻을 갖는다. 이 시기 바그너는 1838년에 빛 독촉으로 산전수전을 다 걲은 상황이라 좌절과 실망에 가득했으며 메피스토펠레스를 만나는 파우스트의 심경에 공감했다고 한다. 또한 파리에서 아브네크의 지휘로 파리 음악원 관현악단이 연주하는 베토벤의 교향곡 9번을 듣고 깊은 감명을 받았는데, 이것이 이듬해 1월에 파우스트의 서곡으로 쓰여진 이 작품에 조금이라도 영향을 끼쳤으리라는 것은 의심할 여지가 없다. 여기의 라단조 조성의 경우에도 그의 전기에 적혀 있는 것처럼 단순한 정신적 피로나 실의가 반영된 것이 아니라 베토벤의 합창교향곡 조성의 영향을 받은 것을 볼 수 있다. 그렇게 교향곡 작곡을 1839년부터 40년에 걸쳐 파리에서 착수했으나 1악장을 쓴 뒤에 중단했다. 또한 작품의 완성과 동시에 그는 이 서곡(1악장)을 파리 음악원의 연주회에서 연주할 파트보까지 준비하였으나, 실제로는 이루어지지는 않았다. 결국 초연은 4년 반이 지난 후에 드레스덴에서 연주되었고 재연도 이루어졌지만, 이후에 그대로 방치되고 말았다. 그 사이에 그는 리엔치와 방황하는 네덜란드인을 완성하고 탄호이저에도 착수하는 등 분주한 시간을 보냈는데, 그런 바쁜 생활이 이 곡을 잊게 한 것이 아닌가 하는 의견도 있다.',
'바그너는 괴테의 파우스트를 읽고 무엇을 쓰고자 했는가?',
'바그너는 교향곡 작곡을 어디까지 쓴 뒤에 중단했는가?',
'바그너가 파우스트 서곡을 쓸 때 어떤 곡의 영향을 받았는가?',
'1839년 바그너가 교향곡의 소재로 쓰려고 했던 책은?',
'파우스트 서곡의 라단조 조성이 영향을 받은 베토벤의 곡은?',
'바그너가 파우스트를 처음으로 읽은 년도는?',
'바그너가 처음 교향곡 작곡을 한 장소는?',
'바그너의 1악장의 초연은 어디서 연주되었는가?']# documents를 전부 이어 하나의 문장으로 만들면 이렇게 보입니다.
" ".join(documents[:10])'파우스트_서곡 1839년 바그너는 괴테의 파우스트을 처음 읽고 그 내용에 마음이 끌려 이를 소재로 해서 하나의 교향곡을 쓰려는 뜻을 갖는다. 이 시기 바그너는 1838년에 빛 독촉으로 산전수전을 다 걲은 상황이라 좌절과 실망에 가득했으며 메피스토펠레스를 만나는 파우스트의 심경에 공감했다고 한다. 또한 파리에서 아브네크의 지휘로 파리 음악원 관현악단이 연주하는 베토벤의 교향곡 9번을 듣고 깊은 감명을 받았는데, 이것이 이듬해 1월에 파우스트의 서곡으로 쓰여진 이 작품에 조금이라도 영향을 끼쳤으리라는 것은 의심할 여지가 없다. 여기의 라단조 조성의 경우에도 그의 전기에 적혀 있는 것처럼 단순한 정신적 피로나 실의가 반영된 것이 아니라 베토벤의 합창교향곡 조성의 영향을 받은 것을 볼 수 있다. 그렇게 교향곡 작곡을 1839년부터 40년에 걸쳐 파리에서 착수했으나 1악장을 쓴 뒤에 중단했다. 또한 작품의 완성과 동시에 그는 이 서곡(1악장)을 파리 음악원의 연주회에서 연주할 파트보까지 준비하였으나, 실제로는 이루어지지는 않았다. 결국 초연은 4년 반이 지난 후에 드레스덴에서 연주되었고 재연도 이루어졌지만, 이후에 그대로 방치되고 말았다. 그 사이에 그는 리엔치와 방황하는 네덜란드인을 완성하고 탄호이저에도 착수하는 등 분주한 시간을 보냈는데, 그런 바쁜 생활이 이 곡을 잊게 한 것이 아닌가 하는 의견도 있다. 바그너는 괴테의 파우스트를 읽고 무엇을 쓰고자 했는가? 바그너는 교향곡 작곡을 어디까지 쓴 뒤에 중단했는가? 바그너가 파우스트 서곡을 쓸 때 어떤 곡의 영향을 받았는가? 1839년 바그너가 교향곡의 소재로 쓰려고 했던 책은? 파우스트 서곡의 라단조 조성이 영향을 받은 베토벤의 곡은? 바그너가 파우스트를 처음으로 읽은 년도는? 바그너가 처음 교향곡 작곡을 한 장소는? 바그너의 1악장의 초연은 어디서 연주되었는가?'❗ Colab에서 실행시 파이썬의 그래프 라이브러리인 matplotlib의 기본 폰트 지원이 안되니 아래의 코드를 실행하면 해결 가능하다.❗
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
mpl.font_manager._rebuild()The following package was automatically installed and is no longer required:
libnvidia-common-470
Use 'apt autoremove' to remove it.
The following NEW packages will be installed:
fonts-nanum
0 upgraded, 1 newly installed, 0 to remove and 39 not upgraded.
Need to get 9,604 kB of archives.
After this operation, 29.5 MB of additional disk space will be used.
Selecting previously unselected package fonts-nanum.
(Reading database ... 155320 files and directories currently installed.)
Preparing to unpack .../fonts-nanum_20170925-1_all.deb ...
Unpacking fonts-nanum (20170925-1) ...
Setting up fonts-nanum (20170925-1) ...
Processing triggers for fontconfig (2.12.6-0ubuntu2) ...# WordCloud로 " ".join(documents)를 처리해 봅니다.
wordcloud = WordCloud(
width=800,
height=800,
background_color='white',
colormap='Accent_r',
font_path=fontpath
).generate(" ".join(documents))
plt.figure(figsize=(10, 10))
# image 출력, interpolation 이미지 시각화 옵션
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
KorQuAD 데이터셋 전처리 (9) 데이터 로드
지금까지 만든 데이터셋을 메모리에 로드한다.
train_json = os.path.join(data_dir, "korquad_train.json")
dev_json = os.path.join(data_dir, "korquad_dev.json")class Config(dict):
"""
json을 config 형태로 사용하기 위한 Class
:param dict: config dictionary
"""
__getattr__ = dict.__getitem__
__setattr__ = dict.__setitem__
args = Config({
'max_seq_length': 384,
'max_query_length': 64,
})
args{'max_query_length': 64, 'max_seq_length': 384}# 생성한 데이터셋 파일을 메모리에 로딩하는 함수
def load_data(args, filename):
inputs, segments, labels_start, labels_end = [], [], [], []
n_discard = 0
with open(filename, "r") as f:
for i, line in enumerate(tqdm(f, desc=f"Loading ...")):
data = json.loads(line)
token_start = data.get("token_start")
token_end = data.get("token_end")
question = data["question"][:args.max_query_length]
context = data["context"]
answer_tokens = " ".join(context[token_start:token_end + 1])
context_len = args.max_seq_length - len(question) - 3
if token_end >= context_len:
# 최대 길이내에 token이 들어가지 않은 경우 처리하지 않음
n_discard += 1
continue
context = context[:context_len]
assert len(question) + len(context) <= args.max_seq_length - 3
tokens = ['[CLS]'] + question + ['[SEP]'] + context + ['[SEP]']
ids = [vocab.piece_to_id(token) for token in tokens]
ids += [0] * (args.max_seq_length - len(ids))
inputs.append(ids)
segs = [0] * (len(question) + 2) + [1] * (len(context) + 1)
segs += [0] * (args.max_seq_length - len(segs))
segments.append(segs)
token_start += (len(question) + 2)
labels_start.append(token_start)
token_end += (len(question) + 2)
labels_end.append(token_end)
print(f'n_discard: {n_discard}')
return (np.array(inputs), np.array(segments)), (np.array(labels_start), np.array(labels_end))# 생성한 데이터셋 파일을 메모리에 로딩하는 함수
def load_data(args, filename):
inputs, segments, labels_start, labels_end = [], [], [], []
n_discard = 0
with open(filename, "r") as f:
for i, line in enumerate(tqdm(f, desc=f"Loading ...")):
data = json.loads(line)
token_start = data.get("token_start")
token_end = data.get("token_end")
question = data["question"][:args.max_query_length]
context = data["context"]
answer_tokens = " ".join(context[token_start:token_end + 1])
context_len = args.max_seq_length - len(question) - 3
if token_end >= context_len:
# 최대 길이내에 token이 들어가지 않은 경우 처리하지 않음
n_discard += 1
continue
context = context[:context_len]
assert len(question) + len(context) <= args.max_seq_length - 3
tokens = ['[CLS]'] + question + ['[SEP]'] + context + ['[SEP]']
ids = [vocab.piece_to_id(token) for token in tokens]
ids += [0] * (args.max_seq_length - len(ids))
inputs.append(ids)
segs = [0] * (len(question) + 2) + [1] * (len(context) + 1)
segs += [0] * (args.max_seq_length - len(segs))
segments.append(segs)
token_start += (len(question) + 2)
labels_start.append(token_start)
token_end += (len(question) + 2)
labels_end.append(token_end)
print(f'n_discard: {n_discard}')
return (np.array(inputs), np.array(segments)), (np.array(labels_start), np.array(labels_end))# train data load
train_inputs, train_labels = load_data(args, train_json)
print(f"train_inputs: {train_inputs[0].shape}")
print(f"train_inputs: {train_inputs[1].shape}")
print(f"train_labels: {train_labels[0].shape}")
print(f"train_labels: {train_labels[1].shape}")
# dev data load
dev_inputs, dev_labels = load_data(args, dev_json)
print(f"dev_inputs: {dev_inputs[0].shape}")
print(f"dev_inputs: {dev_inputs[1].shape}")
print(f"dev_labels: {dev_labels[0].shape}")
print(f"dev_labels: {dev_labels[1].shape}")
train_inputs[:10], train_labels[:10]n_discard: 430
train_inputs: (59977, 384)
train_inputs: (59977, 384)
train_labels: (59977,)
train_labels: (59977,)n_discard: 78
dev_inputs: (5696, 384)
dev_inputs: (5696, 384)
dev_labels: (5696,)
dev_labels: (5696,)((array([[ 5, 15798, 10, ..., 0, 0, 0],
[ 5, 15798, 10, ..., 0, 0, 0],
[ 5, 15798, 19, ..., 0, 0, 0],
...,
[ 5, 21666, 19, ..., 0, 0, 0],
[ 5, 964, 16865, ..., 0, 0, 0],
[ 5, 365, 15, ..., 0, 0, 0]]),
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])),
(array([ 37, 184, 98, ..., 74, 190, 35]),
array([ 37, 185, 102, ..., 75, 191, 44])))✅ 최종으로 만든 데이터셋은 이런 모양이다. ✅
# Question과 Context가 포함된 입력데이터 1번째
train_inputs[0][0]array([ 5, 15798, 10, 28935, 9, 11, 29566, 20, 14604,
20424, 3904, 70, 11, 4648, 10, 19, 1910, 4,
22070, 15, 15798, 10, 28935, 9, 11, 29566, 16,
626, 14604, 38, 14028, 11773, 13829, 384, 8376, 3021,
1239, 6874, 16, 1687, 5958, 2694, 5061, 7, 30,
1613, 15798, 10, 28065, 75, 4415, 1816, 4978, 27,
347, 145, 107, 2703, 263, 11, 1, 18, 5853,
99, 9677, 24, 11969, 13, 7595, 437, 1019, 5907,
257, 3794, 1972, 20, 11278, 11, 29566, 9, 612,
12631, 13214, 1732, 76, 7, 110, 8802, 17581, 354,
9648, 2060, 21, 1682, 22110, 18164, 17, 21076, 14980,
9, 6874, 81, 11325, 4239, 3597, 1010, 1035, 17670,
8, 2447, 1306, 35, 443, 11, 29566, 9, 315,
12729, 14457, 30, 7938, 3742, 10766, 634, 9971, 17590,
19424, 10, 285, 4080, 61, 17573, 483, 7, 7588,
9, 473, 338, 147, 1924, 9, 11016, 136, 1034,
13, 11672, 40, 3436, 5217, 7898, 11684, 57, 830,
9, 19, 3319, 86, 220, 464, 14980, 9, 20515,
412, 991, 684, 1924, 9, 634, 920, 144, 430,
34, 25, 7, 4210, 6874, 2150, 16, 22070, 298,
1159, 75, 1098, 8802, 7490, 805, 35, 18678, 16,
1657, 1970, 2272, 53, 7, 110, 6559, 2178, 24,
756, 82, 30, 315, 684, 3772, 18678, 12, 16,
1682, 22110, 9, 22469, 22, 1757, 61, 8817, 194,
164, 1693, 749, 8, 6739, 12202, 10, 494, 7,
502, 12181, 18, 46, 15, 374, 17, 1680, 708,
26344, 22, 1757, 432, 465, 351, 32, 18563, 710,
8, 2585, 1384, 16071, 265, 3360, 7, 38, 747,
82, 383, 678, 200, 26, 590, 1281, 41, 1172,
31, 16, 2178, 43, 3044, 156, 17, 647, 468,
7490, 41, 84, 758, 92, 33, 3401, 369, 18319,
8, 2582, 29798, 1102, 17, 30, 4573, 11170, 139,
58, 220, 773, 19, 211, 23824, 25, 7, 4,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0])# Question을 0으로, Context를 1로 구분해 준 Segment 데이터 1번째
train_inputs[1][0]array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0])# Answer위치의 시작점과 끝점 라벨 1번째
train_labels[0][0], train_labels[1][0](37, 37)2. LSTM을 이용해보자.
우선 KorQuAD 태스크를 LSTM 모델을 활용하여 학습해 보자.
다소 복잡해 보이겠지만 Input이 2개, Output이 2개인 모델이라는 점에 주목하자.
2개의 Input은 이전 스텝에서 보았던 train_inputs[0], train_inputs[1] 이 들어간다.
각각 Question+Context의 데이터와 Segment이다.
그리고 Output은 Answer의 시작점과 끝점의 위치입니다.
def build_model_lstm(n_vocab, n_seq, d_model):
tokens = tf.keras.layers.Input((None,), name='tokens')
segments = tf.keras.layers.Input((None,), name='segments')
hidden = tf.keras.layers.Embedding(n_vocab, d_model)(tokens) + tf.keras.layers.Embedding(2, d_model)(segments) # (bs, n_seq, d_model)
hidden = tf.keras.layers.LSTM(d_model, return_sequences=True)(hidden) # (bs, n_seq, d_model)
hidden = tf.keras.layers.LSTM(d_model, return_sequences=True)(hidden) # (bs, n_seq, d_model)
hidden = tf.keras.layers.Dense(2)(hidden) # (bs, n_seq, 2)
start_logits, end_logits = tf.split(hidden, 2, axis=-1) # (bs, n_seq, 1), (bs, n_seq, 1)
start_logits = tf.squeeze(start_logits, axis=-1) # (bs, n_seq)
start_outputs = tf.keras.layers.Softmax(name="start")(start_logits)
end_logits = tf.squeeze(end_logits, axis=-1) # (bs, n_seq)
end_outputs = tf.keras.layers.Softmax(name="end")(end_logits)
model = tf.keras.Model(inputs=(tokens, segments), outputs=(start_outputs, end_outputs))
return modelmodel = build_model_lstm(n_vocab=len(vocab), n_seq=512, d_model=512)
tf.keras.utils.plot_model(model, 'model.png', show_shapes=True)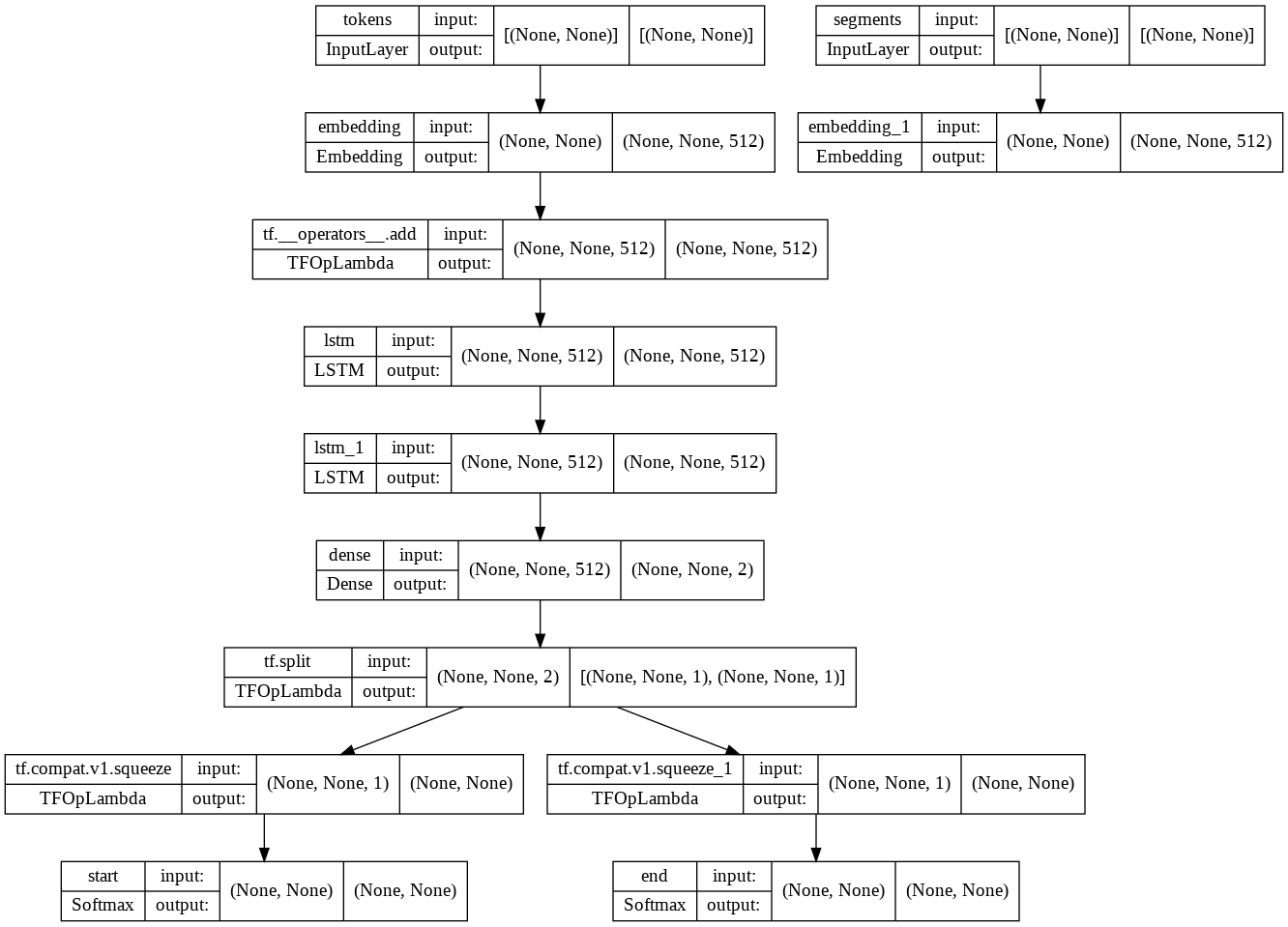
model.compile(loss=tf.keras.losses.sparse_categorical_crossentropy, optimizer=tf.keras.optimizers.Adam(learning_rate=5e-4), metrics=["accuracy"])✅ 훈련을 진행해 보자. ✅
3 epochs 이상 val_start_accuracy가 좋아지지 않으면 훈련을 종료하도록 Early Stopping을 적용할 것이다.
# early stopping
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_start_accuracy', patience=3)
# save weights
save_weights = tf.keras.callbacks.ModelCheckpoint(os.path.join(data_dir, "korquad_lstm.hdf5"), monitor='val_start_accuracy', verbose=1, save_best_only=True, mode='max', save_freq='epoch', save_weights_only=True)
history = model.fit(train_inputs, train_labels, epochs=10, batch_size=128, validation_data=(dev_inputs, dev_labels), callbacks=[early_stopping, save_weights])Epoch 1/10
469/469 [==============================] - ETA: 0s - loss: 9.1250 - start_loss: 4.4188 - end_loss: 4.7061 - start_accuracy: 0.0683 - end_accuracy: 0.0525
Epoch 1: val_start_accuracy improved from -inf to 0.09182, saving model to /content/drive/MyDrive/AIFFEL/data/bert_qna/data/korquad_lstm.hdf5
469/469 [==============================] - 133s 268ms/step - loss: 9.1250 - start_loss: 4.4188 - end_loss: 4.7061 - start_accuracy: 0.0683 - end_accuracy: 0.0525 - val_loss: 8.2428 - val_start_loss: 3.9169 - val_end_loss: 4.3258 - val_start_accuracy: 0.0918 - val_end_accuracy: 0.0797
Epoch 2/10
469/469 [==============================] - ETA: 0s - loss: 7.2976 - start_loss: 3.4785 - end_loss: 3.8192 - start_accuracy: 0.1254 - end_accuracy: 0.1168
Epoch 2: val_start_accuracy improved from 0.09182 to 0.09831, saving model to /content/drive/MyDrive/AIFFEL/data/bert_qna/data/korquad_lstm.hdf5
469/469 [==============================] - 127s 270ms/step - loss: 7.2976 - start_loss: 3.4785 - end_loss: 3.8192 - start_accuracy: 0.1254 - end_accuracy: 0.1168 - val_loss: 8.1880 - val_start_loss: 3.8899 - val_end_loss: 4.2981 - val_start_accuracy: 0.0983 - val_end_accuracy: 0.0751
Epoch 3/10
469/469 [==============================] - ETA: 0s - loss: 6.6995 - start_loss: 3.2164 - end_loss: 3.4831 - start_accuracy: 0.1548 - end_accuracy: 0.1487
Epoch 3: val_start_accuracy did not improve from 0.09831
469/469 [==============================] - 126s 268ms/step - loss: 6.6995 - start_loss: 3.2164 - end_loss: 3.4831 - start_accuracy: 0.1548 - end_accuracy: 0.1487 - val_loss: 8.5488 - val_start_loss: 4.0727 - val_end_loss: 4.4761 - val_start_accuracy: 0.0964 - val_end_accuracy: 0.0785
Epoch 4/10
469/469 [==============================] - ETA: 0s - loss: 6.2355 - start_loss: 3.0143 - end_loss: 3.2212 - start_accuracy: 0.1802 - end_accuracy: 0.1779
Epoch 4: val_start_accuracy did not improve from 0.09831
469/469 [==============================] - 126s 268ms/step - loss: 6.2355 - start_loss: 3.0143 - end_loss: 3.2212 - start_accuracy: 0.1802 - end_accuracy: 0.1779 - val_loss: 8.9480 - val_start_loss: 4.2820 - val_end_loss: 4.6659 - val_start_accuracy: 0.0894 - val_end_accuracy: 0.0725
Epoch 5/10
469/469 [==============================] - ETA: 0s - loss: 5.7086 - start_loss: 2.7857 - end_loss: 2.9229 - start_accuracy: 0.2180 - end_accuracy: 0.2172
Epoch 5: val_start_accuracy improved from 0.09831 to 0.10428, saving model to /content/drive/MyDrive/AIFFEL/data/bert_qna/data/korquad_lstm.hdf5
469/469 [==============================] - 127s 272ms/step - loss: 5.7086 - start_loss: 2.7857 - end_loss: 2.9229 - start_accuracy: 0.2180 - end_accuracy: 0.2172 - val_loss: 8.8777 - val_start_loss: 4.2643 - val_end_loss: 4.6135 - val_start_accuracy: 0.1043 - val_end_accuracy: 0.0981
Epoch 6/10
469/469 [==============================] - ETA: 0s - loss: 4.8064 - start_loss: 2.3566 - end_loss: 2.4498 - start_accuracy: 0.3110 - end_accuracy: 0.3077
Epoch 6: val_start_accuracy improved from 0.10428 to 0.13220, saving model to /content/drive/MyDrive/AIFFEL/data/bert_qna/data/korquad_lstm.hdf5
469/469 [==============================] - 127s 270ms/step - loss: 4.8064 - start_loss: 2.3566 - end_loss: 2.4498 - start_accuracy: 0.3110 - end_accuracy: 0.3077 - val_loss: 9.4845 - val_start_loss: 4.4758 - val_end_loss: 5.0088 - val_start_accuracy: 0.1322 - val_end_accuracy: 0.1215
Epoch 7/10
469/469 [==============================] - ETA: 0s - loss: 4.0516 - start_loss: 1.9859 - end_loss: 2.0657 - start_accuracy: 0.3956 - end_accuracy: 0.3856
Epoch 7: val_start_accuracy improved from 0.13220 to 0.13483, saving model to /content/drive/MyDrive/AIFFEL/data/bert_qna/data/korquad_lstm.hdf5
469/469 [==============================] - 127s 270ms/step - loss: 4.0516 - start_loss: 1.9859 - end_loss: 2.0657 - start_accuracy: 0.3956 - end_accuracy: 0.3856 - val_loss: 10.5363 - val_start_loss: 4.9508 - val_end_loss: 5.5855 - val_start_accuracy: 0.1348 - val_end_accuracy: 0.1285
Epoch 8/10
469/469 [==============================] - ETA: 0s - loss: 3.4047 - start_loss: 1.6777 - end_loss: 1.7270 - start_accuracy: 0.4695 - end_accuracy: 0.4649
Epoch 8: val_start_accuracy improved from 0.13483 to 0.13852, saving model to /content/drive/MyDrive/AIFFEL/data/bert_qna/data/korquad_lstm.hdf5
469/469 [==============================] - 127s 270ms/step - loss: 3.4047 - start_loss: 1.6777 - end_loss: 1.7270 - start_accuracy: 0.4695 - end_accuracy: 0.4649 - val_loss: 11.5907 - val_start_loss: 5.4844 - val_end_loss: 6.1063 - val_start_accuracy: 0.1385 - val_end_accuracy: 0.1383
Epoch 9/10
469/469 [==============================] - ETA: 0s - loss: 2.7951 - start_loss: 1.3808 - end_loss: 1.4143 - start_accuracy: 0.5508 - end_accuracy: 0.5484
Epoch 9: val_start_accuracy did not improve from 0.13852
469/469 [==============================] - 126s 269ms/step - loss: 2.7951 - start_loss: 1.3808 - end_loss: 1.4143 - start_accuracy: 0.5508 - end_accuracy: 0.5484 - val_loss: 12.8467 - val_start_loss: 6.0741 - val_end_loss: 6.7725 - val_start_accuracy: 0.1354 - val_end_accuracy: 0.1285
Epoch 10/10
469/469 [==============================] - ETA: 0s - loss: 2.2430 - start_loss: 1.1107 - end_loss: 1.1323 - start_accuracy: 0.6319 - end_accuracy: 0.6285
Epoch 10: val_start_accuracy did not improve from 0.13852
469/469 [==============================] - 127s 271ms/step - loss: 2.2430 - start_loss: 1.1107 - end_loss: 1.1323 - start_accuracy: 0.6319 - end_accuracy: 0.6285 - val_loss: 14.4868 - val_start_loss: 6.9055 - val_end_loss: 7.5814 - val_start_accuracy: 0.1364 - val_end_accuracy: 0.1310✅ 시각화를 해보자. ✅
# training result
plt.figure(figsize=(16, 4))
plt.subplot(1, 3, 1)
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('Epoch')
plt.legend()
plt.subplot(1, 3, 2)
plt.plot(history.history['start_accuracy'], 'g-', label='start_accuracy')
plt.plot(history.history['val_start_accuracy'], 'k--', label='val_start_accuracy')
plt.xlabel('Epoch')
plt.legend()
plt.subplot(1, 3, 3)
plt.plot(history.history['end_accuracy'], 'b-', label='end_accuracy')
plt.plot(history.history['val_end_accuracy'], 'g--', label='val_end_accuracy')
plt.xlabel('Epoch')
plt.legend()
plt.show()findfont: Font family ['NanumBarunGothic'] not found. Falling back to DejaVu Sans.
LSTM을 통해 진행했던 결과값은 val_loss 가 낮아지지 않고, val_accuracy 들도 크게 좋아지지 않는 것을 알 수 있다.
KorQuAD 태스크는 데이터셋만 가지고 사전 준비 없이 학습했을 때 일정 이상 좋아지지 않는다는 것을 알 수 있다.
모델을 다양하게 바꾸어 보아도 결과는 비슷할 것이다.
그렇다면 어떻게 해야 이 태스크를 학습할 수 있을까❓❓❓
3. BERT의 모델 구조

Transformer 모델은 Self-Attention으로 이루어진 Encoder-Decoder 구조를 가지고 있어서 번역기 모델 형태를 구현하는데 적당하다.
BERT는 여기서 Transformer Encoder 구조만을 활용한다.
Layer 개수는 12개 이상으로 늘리고, 전체적으로 파라미터 크기가 훨씬 커지긴 했지만 기본적인 구조는 동일하다.
그런데 Decoder가 없다면 이 모델은 어떻게 학습시키는 걸까❓❓❓
위 그림의 왼쪽을 보면 BERT의 입력을 Transformer Encoder에 넣었을 때, 출력 모델이 Mask LM, NSP라는 2가지 문제를 해결하도록 되어 있다.
✅ 각각 내용들을 살펴보자.
Mask LM
입력 데이터가 나는 <mask> 먹었다 일 때 BERT 모델이 <mask> 가 밥을 임을 맞출 수 있도록 하는 언어 모델이다.
이전의 Next Token Prediction Language Model과 대비시켜 이른바 다음 빈칸에 알맞은 말은 문제를 엄청나게 풀어보는 언어 모델을 구현한 것이다.
Next Sentence Prediction
이 경우는 입력 데이터가 나는 밥을 먹었다. <SEP> 그래서 지금 배가 부르다. 가 주어졌을 때 <SEP>를 경계로 좌우 두 문장이 순서대로 이어지는 문장이 맞는지를 맞추는 문제이다.
BERT 모델은 이 두 문장을 입력으로 받았을 때 첫 번째 바이트에 NSP 결괏값을 리턴하게 된다.

여기서 주목할 것은 바로 위 그림에 나타나는 BERT 모델의 입력 부분이다.
텍스트 입력이 위 그림의 [Input]처럼 주어졌을 때, 실제로 모델에 입력되는 것은 Token, Segment, Position Embedding의 3가지가 더해진 형태이다.
실제로는 그 이후 layer normalization과 dropout이 추가로 적용된다.
각각의 역할은 다음과 같습니다.
- Token Embedding
BERT는 텍스트의 tokenizer로 Word Piece model이라는 subword tokenizer를 사용한다.
문자(char) 단위로 임베딩 하는 것이 기본이지만, 자주 등장하는 긴 길이의 subword도 하나의 단위로 만들어 준다.
자주 등장하지 않는 단어는 다시 subword 단위로 쪼개진다.
이것은 자주 등장하지 않는 단어가 OOV(Out-of-vocabulary) 처리되는 것을 방지해 주는 장점도 있다.
그래서 최종적으로 Word Piece모델의 각 임베딩이 입력된다.
- Segment Embedding
기존 Transformer에 없던 독특한 임베딩이다.
이것은 각 단어가 어느 문장에 포함되는지 그 역할을 규정하는 것이다.
이전 스텝에서 KorQuAD 데이터셋을 분석하면서 살펴보았지만, 특히 QA 문제처럼 이 단어가 Question 문장에 속하는지, Context 문장에 속하는지 구분이 필요한 경우에 이 임베딩은 매우 유용하게 사용된다.
- Position Embedding
이 임베딩은 기존의 Transformer에서 사용되던 position embedding과 동일하다.
✅ 그러면 이제 실제 코드를 통해 BERT 모델 구성을 더욱 디테일하게 살펴보자.
# 유틸리티 함수들
def get_pad_mask(tokens, i_pad=0):
"""
pad mask 계산하는 함수
:param tokens: tokens (bs, n_seq)
:param i_pad: id of pad
:return mask: pad mask (pad: 1, other: 0)
"""
mask = tf.cast(tf.math.equal(tokens, i_pad), tf.float32)
mask = tf.expand_dims(mask, axis=1)
return mask
def get_ahead_mask(tokens, i_pad=0):
"""
ahead mask 계산하는 함수
:param tokens: tokens (bs, n_seq)
:param i_pad: id of pad
:return mask: ahead and pad mask (ahead or pad: 1, other: 0)
"""
n_seq = tf.shape(tokens)[1]
ahead_mask = 1 - tf.linalg.band_part(tf.ones((n_seq, n_seq)), -1, 0)
ahead_mask = tf.expand_dims(ahead_mask, axis=0)
pad_mask = get_pad_mask(tokens, i_pad)
mask = tf.maximum(ahead_mask, pad_mask)
return mask
@tf.function(experimental_relax_shapes=True)
def gelu(x):
"""
gelu activation 함수
:param x: 입력 값
:return: gelu activation result
"""
return 0.5 * x * (1 + K.tanh(x * 0.7978845608 * (1 + 0.044715 * x * x)))
def kernel_initializer(stddev=0.02):
"""
parameter initializer 생성
:param stddev: 생성할 랜덤 변수의 표준편차
"""
return tf.keras.initializers.TruncatedNormal(stddev=stddev)
def bias_initializer():
"""
bias initializer 생성
"""
return tf.zeros_initializer
class Config(dict):
"""
json을 config 형태로 사용하기 위한 Class
:param dict: config dictionary
"""
__getattr__ = dict.__getitem__
__setattr__ = dict.__setitem__
@classmethod
def load(cls, file):
"""
file에서 Config를 생성 함
:param file: filename
"""
with open(file, 'r') as f:
config = json.loads(f.read())
return Config(config)# mode == "embedding" 일 경우 Token Embedding Layer 로 사용되는 layer 클래스입니다.
class SharedEmbedding(tf.keras.layers.Layer):
"""
Weighed Shared Embedding Class
"""
def __init__(self, config, name="weight_shared_embedding"):
"""
생성자
:param config: Config 객체
:param name: layer name
"""
super().__init__(name=name)
self.n_vocab = config.n_vocab
self.d_model = config.d_model
def build(self, input_shape):
"""
shared weight 생성
:param input_shape: Tensor Shape (not used)
"""
with tf.name_scope("shared_embedding_weight"):
self.shared_weights = self.add_weight(
"weights",
shape=[self.n_vocab, self.d_model],
initializer=kernel_initializer()
)
def call(self, inputs, mode="embedding"):
"""
layer 실행
:param inputs: 입력
:param mode: 실행 모드
:return: embedding or linear 실행 결과
"""
# mode가 embedding일 경우 embedding lookup 실행
if mode == "embedding":
return self._embedding(inputs)
# mode가 linear일 경우 linear 실행
elif mode == "linear":
return self._linear(inputs)
# mode가 기타일 경우 오류 발생
else:
raise ValueError(f"mode {mode} is not valid.")
def _embedding(self, inputs):
"""
embedding lookup
:param inputs: 입력
"""
embed = tf.gather(self.shared_weights, tf.cast(inputs, tf.int32))
return embed
def _linear(self, inputs): # (bs, n_seq, d_model)
"""
linear 실행
:param inputs: 입력
"""
n_batch = tf.shape(inputs)[0]
n_seq = tf.shape(inputs)[1]
inputs = tf.reshape(inputs, [-1, self.d_model]) # (bs * n_seq, d_model)
outputs = tf.matmul(inputs, self.shared_weights, transpose_b=True)
outputs = tf.reshape(outputs, [n_batch, n_seq, self.n_vocab]) # (bs, n_seq, n_vocab)
return outputsclass PositionalEmbedding(tf.keras.layers.Layer):
"""
Positional Embedding Class
"""
def __init__(self, config, name="position_embedding"):
"""
생성자
:param config: Config 객체
:param name: layer name
"""
super().__init__(name=name)
self.embedding = tf.keras.layers.Embedding(config.n_seq, config.d_model, embeddings_initializer=kernel_initializer())
def call(self, inputs):
"""
layer 실행
:param inputs: 입력
:return embed: positional embedding lookup 결과
"""
position = tf.cast(tf.math.cumsum(tf.ones_like(inputs), axis=1, exclusive=True), tf.int32)
embed = self.embedding(position)
return embedclass ScaleDotProductAttention(tf.keras.layers.Layer):
"""
Scale Dot Product Attention Class
"""
def __init__(self, name="scale_dot_product_attention"):
"""
생성자
:param name: layer name
"""
super().__init__(name=name)
def call(self, Q, K, V, attn_mask):
"""
layer 실행
:param Q: Q value
:param K: K value
:param V: V value
:param attn_mask: 실행 모드
:return attn_out: attention 실행 결과
"""
attn_score = tf.matmul(Q, K, transpose_b=True)
scale = tf.math.sqrt(tf.cast(tf.shape(K)[-1], tf.float32))
attn_scale = tf.math.divide(attn_score, scale)
attn_scale -= 1.e9 * attn_mask
attn_prob = tf.nn.softmax(attn_scale, axis=-1)
attn_out = tf.matmul(attn_prob, V)
return attn_outclass MultiHeadAttention(tf.keras.layers.Layer):
"""
Multi Head Attention Class
"""
def __init__(self, config, name="multi_head_attention"):
"""
생성자
:param config: Config 객체
:param name: layer name
"""
super().__init__(name=name)
self.d_model = config.d_model
self.n_head = config.n_head
self.d_head = config.d_head
# Q, K, V input dense layer
self.W_Q = tf.keras.layers.Dense(config.n_head * config.d_head, kernel_initializer=kernel_initializer(), bias_initializer=bias_initializer())
self.W_K = tf.keras.layers.Dense(config.n_head * config.d_head, kernel_initializer=kernel_initializer(), bias_initializer=bias_initializer())
self.W_V = tf.keras.layers.Dense(config.n_head * config.d_head, kernel_initializer=kernel_initializer(), bias_initializer=bias_initializer())
# Scale Dot Product Attention class
self.attention = ScaleDotProductAttention(name="self_attention")
# output dense layer
self.W_O = tf.keras.layers.Dense(config.d_model, kernel_initializer=kernel_initializer(), bias_initializer=bias_initializer())
def call(self, Q, K, V, attn_mask):
"""
layer 실행
:param Q: Q value
:param K: K value
:param V: V value
:param attn_mask: 실행 모드
:return attn_out: attention 실행 결과
"""
# reshape Q, K, V, attn_mask
batch_size = tf.shape(Q)[0]
Q_m = tf.transpose(tf.reshape(self.W_Q(Q), [batch_size, -1, self.n_head, self.d_head]), [0, 2, 1, 3]) # (bs, n_head, Q_len, d_head)
K_m = tf.transpose(tf.reshape(self.W_K(K), [batch_size, -1, self.n_head, self.d_head]), [0, 2, 1, 3]) # (bs, n_head, K_len, d_head)
V_m = tf.transpose(tf.reshape(self.W_V(V), [batch_size, -1, self.n_head, self.d_head]), [0, 2, 1, 3]) # (bs, n_head, K_len, d_head)
attn_mask_m = tf.expand_dims(attn_mask, axis=1)
# Scale Dot Product Attention with multi head Q, K, V, attn_mask
attn_out = self.attention(Q_m, K_m, V_m, attn_mask_m) # (bs, n_head, Q_len, d_head)
# transpose and liner
attn_out_m = tf.transpose(attn_out, perm=[0, 2, 1, 3]) # (bs, Q_len, n_head, d_head)
attn_out = tf.reshape(attn_out_m, [batch_size, -1, config.n_head * config.d_head]) # (bs, Q_len, d_model)
attn_out = self.W_O(attn_out) # (bs, Q_len, d_model)
return attn_outclass PositionWiseFeedForward(tf.keras.layers.Layer):
"""
Position Wise Feed Forward Class
"""
def __init__(self, config, name="feed_forward"):
"""
생성자
:param config: Config 객체
:param name: layer name
"""
super().__init__(name=name)
self.W_1 = tf.keras.layers.Dense(config.d_ff, activation=gelu, kernel_initializer=kernel_initializer(), bias_initializer=bias_initializer())
self.W_2 = tf.keras.layers.Dense(config.d_model, kernel_initializer=kernel_initializer(), bias_initializer=bias_initializer())
def call(self, inputs):
"""
layer 실행
:param inputs: inputs
:return ff_val: feed forward 실행 결과
"""
ff_val = self.W_2(self.W_1(inputs))
return ff_valclass EncoderLayer(tf.keras.layers.Layer):
"""
Encoder Layer Class
"""
def __init__(self, config, name="encoder_layer"):
"""
생성자
:param config: Config 객체
:param name: layer name
"""
super().__init__(name=name)
self.self_attention = MultiHeadAttention(config)
self.norm1 = tf.keras.layers.LayerNormalization(epsilon=config.layernorm_epsilon)
self.ffn = PositionWiseFeedForward(config)
self.norm2 = tf.keras.layers.LayerNormalization(epsilon=config.layernorm_epsilon)
self.dropout = tf.keras.layers.Dropout(config.dropout)
def call(self, enc_embed, self_mask):
"""
layer 실행
:param enc_embed: enc_embed 또는 이전 EncoderLayer의 출력
:param self_mask: enc_tokens의 pad mask
:return enc_out: EncoderLayer 실행 결과
"""
self_attn_val = self.self_attention(enc_embed, enc_embed, enc_embed, self_mask)
norm1_val = self.norm1(enc_embed + self.dropout(self_attn_val))
ffn_val = self.ffn(norm1_val)
enc_out = self.norm2(norm1_val + self.dropout(ffn_val))
return enc_out위와 같이 BERT를 구성하는 레이어들이 준비되었다.
아래 BERT 모델 구현을 통해 위에서 설명했던 레이어들이 어떻게 서로 결합되어 있는지 살펴보자.
class BERT(tf.keras.layers.Layer):
"""
BERT Class
"""
def __init__(self, config, name="bert"):
"""
생성자
:param config: Config 객체
:param name: layer name
"""
super().__init__(name=name)
self.i_pad = config.i_pad
self.embedding = SharedEmbedding(config)
self.position = PositionalEmbedding(config)
self.segment = tf.keras.layers.Embedding(2, config.d_model, embeddings_initializer=kernel_initializer())
self.norm = tf.keras.layers.LayerNormalization(epsilon=config.layernorm_epsilon)
self.encoder_layers = [EncoderLayer(config, name=f"encoder_layer_{i}") for i in range(config.n_layer)]
self.dropout = tf.keras.layers.Dropout(config.dropout)
def call(self, enc_tokens, segments):
"""
layer 실행
:param enc_tokens: encoder tokens
:param segments: token segments
:return logits_cls: CLS 결과 logits
:return logits_lm: LM 결과 logits
"""
enc_self_mask = get_pad_mask(enc_tokens, self.i_pad)
enc_embed = self.get_embedding(enc_tokens, segments)
enc_out = self.dropout(enc_embed)
for encoder_layer in self.encoder_layers:
enc_out = encoder_layer(enc_out, enc_self_mask)
logits_cls = enc_out[:,0]
logits_lm = enc_out
return logits_cls, logits_lm
def get_embedding(self, tokens, segments):
"""
token embedding, position embedding lookup
:param tokens: 입력 tokens
:param segments: 입력 segments
:return embed: embedding 결과
"""
embed = self.embedding(tokens) + self.position(tokens) + self.segment(segments)
embed = self.norm(embed)
return embedclass BERT(tf.keras.layers.Layer):
"""
BERT Class
"""
def __init__(self, config, name="bert"):
"""
생성자
:param config: Config 객체
:param name: layer name
"""
super().__init__(name=name)
self.i_pad = config.i_pad
self.embedding = SharedEmbedding(config)
self.position = PositionalEmbedding(config)
self.segment = tf.keras.layers.Embedding(2, config.d_model, embeddings_initializer=kernel_initializer())
self.norm = tf.keras.layers.LayerNormalization(epsilon=config.layernorm_epsilon)
self.encoder_layers = [EncoderLayer(config, name=f"encoder_layer_{i}") for i in range(config.n_layer)]
self.dropout = tf.keras.layers.Dropout(config.dropout)
def call(self, enc_tokens, segments):
"""
layer 실행
:param enc_tokens: encoder tokens
:param segments: token segments
:return logits_cls: CLS 결과 logits
:return logits_lm: LM 결과 logits
"""
enc_self_mask = get_pad_mask(enc_tokens, self.i_pad)
enc_embed = self.get_embedding(enc_tokens, segments)
enc_out = self.dropout(enc_embed)
for encoder_layer in self.encoder_layers:
enc_out = encoder_layer(enc_out, enc_self_mask)
logits_cls = enc_out[:,0]
logits_lm = enc_out
return logits_cls, logits_lm
def get_embedding(self, tokens, segments):
"""
token embedding, position embedding lookup
:param tokens: 입력 tokens
:param segments: 입력 segments
:return embed: embedding 결과
"""
embed = self.embedding(tokens) + self.position(tokens) + self.segment(segments)
embed = self.norm(embed)
return embed4. BERT 모델을 이용한 도전
BERT 모델을 활용하여, LSTM으로 풀어보았던 KorQuAD 태스크를 다시 학습해 보자.
모델의 차이만 비교해 보기 위해 일부러 두 모델이 사용하는 Tokenizer를 동일하게 구성하다.
아래는 BERT 레이어에 Fully Connected layer를 붙어 KorQuAD용으로 finetune 하기 위한 모델 클래스이다.
class BERT4KorQuAD(tf.keras.Model):
def __init__(self, config):
super().__init__(name='BERT4KorQuAD')
self.bert = BERT(config)
self.dense = tf.keras.layers.Dense(2)
def call(self, enc_tokens, segments):
logits_cls, logits_lm = self.bert(enc_tokens, segments)
hidden = self.dense(logits_lm) # (bs, n_seq, 2)
start_logits, end_logits = tf.split(hidden, 2, axis=-1) # (bs, n_seq, 1), (bs, n_seq, 1)
start_logits = tf.squeeze(start_logits, axis=-1)
start_outputs = tf.keras.layers.Softmax(name="start")(start_logits)
end_logits = tf.squeeze(end_logits, axis=-1)
end_outputs = tf.keras.layers.Softmax(name="end")(end_logits)
return start_outputs, end_outputsconfig = Config({"d_model": 512, "n_head": 8, "d_head": 64, "dropout": 0.1, "d_ff": 1024, "layernorm_epsilon": 0.001, "n_layer": 6, "n_seq": 384, "n_vocab": 0, "i_pad": 0})
config.n_vocab = len(vocab)
config.i_pad = vocab.pad_id()
config{'d_ff': 1024,
'd_head': 64,
'd_model': 512,
'dropout': 0.1,
'i_pad': 0,
'layernorm_epsilon': 0.001,
'n_head': 8,
'n_layer': 6,
'n_seq': 384,
'n_vocab': 32007}Config 을 통해 실제로 우리가 사용할 모델 사이즈를 조정한다.
BERT 논문에 공개된 실제 사이즈는 아래와 같다.
- BERT-base(110M parameters) : 12-layer, 768-hidden, 12-
- BERT-large (336M parameters) : 24-layer, 1024-hidden, 16-heads
그러나 이렇게 거대한 모델을 작은 실습환경에서 다루기에는 무리가 있다.
그래서 BERT의 성능을 조금이라도 체험해 볼 수 있을 정도로 사이즈를 아래와 같이 조정할 것이다.
- Our Tiny Bert(29M parameters) : 6-layer, 512-hidden, 8-heads
모델의 크기가 다르고, 사용할 수 있는 배치 사이즈가 달라지므로, 배치 구성만 다시 진행해보자.
bert_batch_size = 32
train_dataset = tf.data.Dataset.from_tensor_slices((train_inputs, train_labels)).shuffle(10000).batch(bert_batch_size)
dev_dataset = tf.data.Dataset.from_tensor_slices((dev_inputs, dev_labels)).batch(bert_batch_size)model = BERT4KorQuAD(config)✅ 학습을 진행해 보자. ✅
BERT는 사실 pretrained 모델을 활용하는 데 의의가 있다.
이번에는 BERT 모델만 구성한 후 전혀 pretraining 없이 학습을 진행해 보자. 과연 결과가 어떨까❓❓❓
def train_epoch(model, dataset, loss_fn, acc_fn, optimizer):
metric_start_loss = tf.keras.metrics.Mean(name='start_loss')
metric_end_loss = tf.keras.metrics.Mean(name='end_loss')
metric_start_acc = tf.keras.metrics.Mean(name='start_acc')
metric_end_acc = tf.keras.metrics.Mean(name='end_acc')
p_bar = tqdm(dataset)
for batch, ((enc_tokens, segments), (start_labels, end_labels)) in enumerate(p_bar):
with tf.GradientTape() as tape:
start_outputs, end_outputs = model(enc_tokens, segments)
start_loss = loss_fn(start_labels, start_outputs)
end_loss = loss_fn(end_labels, end_outputs)
loss = start_loss + end_loss
start_acc = acc_fn(start_labels, start_outputs)
end_acc = acc_fn(end_labels, end_outputs)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
metric_start_loss(start_loss)
metric_end_loss(end_loss)
metric_start_acc(start_acc)
metric_end_acc(end_acc)
if batch % 10 == 9:
p_bar.set_description(f'loss: {metric_start_loss.result():0.4f}, {metric_end_loss.result():0.4f}, acc: {metric_start_acc.result():0.4f}, {metric_end_acc.result():0.4f}')
p_bar.close()
return metric_start_loss.result(), metric_end_loss.result(), metric_start_acc.result(), metric_end_acc.result()def eval_epoch(model, dataset, loss_fn, acc_fn):
metric_start_loss = tf.keras.metrics.Mean(name='start_loss')
metric_end_loss = tf.keras.metrics.Mean(name='end_loss')
metric_start_acc = tf.keras.metrics.Mean(name='start_acc')
metric_end_acc = tf.keras.metrics.Mean(name='end_acc')
for batch, ((enc_tokens, segments), (start_labels, end_labels)) in enumerate(dataset):
start_outputs, end_outputs = model(enc_tokens, segments)
start_loss = loss_fn(start_labels, start_outputs)
end_loss = loss_fn(end_labels, end_outputs)
start_acc = acc_fn(start_labels, start_outputs)
end_acc = acc_fn(end_labels, end_outputs)
metric_start_loss(start_loss)
metric_end_loss(end_loss)
metric_start_acc(start_acc)
metric_end_acc(end_acc)
return metric_start_loss.result(), metric_end_loss.result(), metric_start_acc.result(), metric_end_acc.result()loss_fn = tf.keras.losses.sparse_categorical_crossentropy
acc_fn = tf.keras.metrics.sparse_categorical_accuracy
optimizer = tf.keras.optimizers.Adam(learning_rate=5e-4)
best_acc = .0
patience = 0
for epoch in range(3):
train_epoch(model, train_dataset, loss_fn, acc_fn, optimizer)
start_loss, end_loss, start_acc, end_acc = eval_epoch(model, dev_dataset, loss_fn, acc_fn)
print(f'eval {epoch} >> loss: {start_loss:0.4f}, {end_loss:0.4f}, acc: {start_acc:0.4f}, {end_acc:0.4f}')
acc = start_acc + end_acc
if best_acc < acc:
patience = 0
best_acc = acc
model.save_weights(os.path.join(data_dir, "korquad_bert_none_pretrain.hdf5"))
print(f'save best model')
else:
patience += 1
if 2 <= patience:
print(f'early stopping')
breakeval 0 >> loss: 5.9506, 5.9506, acc: 0.0098, 0.0009
save best modeleval 1 >> loss: 5.9507, 5.9506, acc: 0.0121, 0.0016
save best modeleval 2 >> loss: 5.9487, 5.9478, acc: 0.0165, 0.0028
save best model아마도 결과는 크게 차이 나지 않을 것이다.
이번 모델에는 수많은 코퍼스를 통해 정교하게 얻어진 Word Embedding이 반영되지 않았기 때문이다.
그렇다면 pretrained model을 활용하여 finetuning 했을 때의 결과는 어떨까❓❓❓
5. Pretrained model의 활용
pretrained model을 활용해 보자.
사용해야 할 모델 구조나 데이터셋 구조, 배치 구조는 이전 스텝과 동일하다.
이미 다운로드한 pretrained model을 활용하는 학습을 다시 진행해 보자.
STEP 1. pretrained model 로딩하기
pretrained model을 로드하여 model을 생성하는 코드는 아래와 같다.
checkpoint_file = os.path.join(model_dir, 'bert_pretrain_32000.hdf5')
model = BERT4KorQuAD(config)
if os.path.exists(checkpoint_file):
# pretrained model 을 로드하기 위해 먼저 모델이 생성되어 있어야 한다.
enc_tokens = np.random.randint(0, len(vocab), (4, 10))
segments = np.random.randint(0, 2, (4, 10))
model(enc_tokens, segments)
# checkpoint 파일로부터 필요한 layer를 불러온다.
model.load_weights(os.path.join(model_dir, "bert_pretrain_32000.hdf5"), by_name=True)
model.summary()
else:
print('NO Pretrained Model')Model: "BERT4KorQuAD"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 29202944
dense_111 (Dense) multiple 1026
=================================================================
Total params: 29,203,970
Trainable params: 29,203,970
Non-trainable params: 0
_________________________________________________________________STEP 2. pretrained model finetune 하기
학습을 진행하는 코드도 이전 스텝과 동일하다.
단지 학습해야 할 모델이 랜덤 초기화된 것이 아니라 pretrained model을 로드한 것이다.
loss_fn = tf.keras.losses.sparse_categorical_crossentropy
acc_fn = tf.keras.metrics.sparse_categorical_accuracy
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-4) # learning rate 5e-4 ----> 3e-4 낮춤, 아담 옵티마이저는 그대로
best_acc = .0
patience = 0
# training값, validation의 각각 accuracy, loss값 tracing
history = {'train_start_loss': [],
'train_end_loss': [],
'train_start_acc': [],
'train_end_acc': [],
'val_start_loss': [],
'val_end_loss': [],
'val_start_acc': [],
'val_end_acc': []}
for epoch in range(3):
# train set 학습
train_epoch(model, train_dataset, loss_fn, acc_fn, optimizer)
start_loss, end_loss, start_acc, end_acc = eval_epoch(model, train_dataset, loss_fn, acc_fn)
print(f'eval {epoch} >> loss: {start_loss:0.4f}, {end_loss:0.4f}, acc: {start_acc:0.4f}, {end_acc:0.4f}')
# 학습과정 시각화
history['train_start_loss'].append(start_loss)
history['train_end_loss'].append(end_loss)
history['train_start_acc'].append(start_acc)
history['train_end_acc'].append(end_acc)
# validation set 학습
train_epoch(model, dev_dataset, loss_fn, acc_fn, optimizer)
start_loss, end_loss, start_acc, end_acc = eval_epoch(model, dev_dataset, loss_fn, acc_fn)
print(f'eval {epoch} >> loss: {start_loss:0.4f}, {end_loss:0.4f}, acc: {start_acc:0.4f}, {end_acc:0.4f}')
# 학습과정 시각화
history['val_start_loss'].append(start_loss)
history['val_end_loss'].append(end_loss)
history['val_start_acc'].append(start_acc)
history['val_end_acc'].append(end_acc)
acc = start_acc + end_acc
if best_acc < acc:
patience = 0
best_acc = acc
model.save_weights(os.path.join(data_dir, "korquad_bert_none_pretrain.hdf5"))
print(f'save best model')
else:
patience += 1
if 2 <= patience:
print(f'early stopping')
breakeval 0 >> loss: 0.9386, 1.1353, acc: 0.7688, 0.7134eval 0 >> loss: 0.5505, 0.6601, acc: 0.8718, 0.8302
save best modeleval 1 >> loss: 0.4476, 0.5802, acc: 0.8759, 0.8447eval 1 >> loss: 0.3041, 0.4540, acc: 0.9250, 0.8811
save best modeleval 2 >> loss: 0.2770, 0.3595, acc: 0.9230, 0.9003eval 2 >> loss: 0.2389, 0.3438, acc: 0.9389, 0.9013
save best modelSTEP 3. Inference 수행하기
finetune 학습이 완료된 model을 활용하여 실제 퀴즈 풀이 결과를 확인해 보자.
def do_predict(model, question, context):
"""
입력에 대한 답변 생성하는 함수
:param model: model
:param question: 입력 문자열
:param context: 입력 문자열
"""
q_tokens = vocab.encode_as_pieces(question)[:args.max_query_length]
c_tokens = vocab.encode_as_pieces(context)[:args.max_seq_length - len(q_tokens) - 3]
tokens = ['[CLS]'] + q_tokens + ['[SEP]'] + c_tokens + ['[SEP]']
token_ids = [vocab.piece_to_id(token) for token in tokens]
segments = [0] * (len(q_tokens) + 2) + [1] * (len(c_tokens) + 1)
y_start, y_end = model(np.array([token_ids]), np.array([segments]))
# print(y_start, y_end)
y_start_idx = K.argmax(y_start, axis=-1)[0].numpy()
y_end_idx = K.argmax(y_end, axis=-1)[0].numpy()
answer_tokens = tokens[y_start_idx:y_end_idx + 1]
return vocab.decode_pieces(answer_tokens)
dev_json = os.path.join(data_dir, "korquad_dev.json")
with open(dev_json) as f:
for i, line in enumerate(f):
data = json.loads(line)
question = vocab.decode_pieces(data['question'])
context = vocab.decode_pieces(data['context'])
answer = data['answer']
answer_predict = do_predict(model, question, context)
if answer in answer_predict:
print(i)
print("질문 : ", question)
print("지문 : ", context)
print("정답 : ", answer)
print("예측 : ", answer_predict, "\n")
if 100 < i:
breakSTEP 4. 학습 경과 시각화 비교 분석
pretrained model 사용 여부에 따라 학습 수행 경과가 어떻게 달라지는지를 시각화를 포함하여 비교 분석을 진행해 보자.
# 훈련이 마무리되었으면 시각화를 진행.
plt.figure(figsize=(16, 10))
plt.subplot(2, 2, 1)
plt.plot(history['train_start_loss'], 'g-', label='train_start_loss')
plt.plot(history['val_start_loss'], 'y--', label='val_start_loss')
plt.xlabel('Epoch')
plt.legend()
plt.title('start-loss')
plt.subplot(2, 2, 2)
plt.plot(history['train_end_loss'], 'g-', label='train_end_loss')
plt.plot(history['val_end_loss'], 'y--', label='val_end_loss')
plt.xlabel('Epoch')
plt.legend()
plt.title('end-loss')
plt.subplot(2, 2, 3)
plt.plot(history['train_start_acc'], 'g-', label='train_start_acc')
plt.plot(history['val_start_acc'], 'y--', label='val_start_acc')
plt.xlabel('Epoch')
plt.legend()
plt.title('start-accuracy')
plt.subplot(2, 2, 4)
plt.plot(history['train_end_acc'], 'g-', label='train_end_acc')
plt.plot(history['val_end_acc'], 'y--', label='val_end_acc')
plt.xlabel('Epoch')
plt.legend()
plt.title('end-accuracy')
plt.show()findfont: Font family ['NanumBarunGothic'] not found. Falling back to DejaVu Sans.
'인공지능' 카테고리의 다른 글
| [Part2]난 스케치 넌 채색을... |TF2-GAN (0) | 2022.03.18 |
|---|---|
| [Part1]난 스케치 넌 채색을... |GAN (0) | 2022.03.18 |
| 트랜스포머로 만드는 대화형 챗봇|Transformer (0) | 2022.02.22 |
| [Part 2]CIFAR-10 을 활용한 이미지 생성기 (0) | 2022.02.16 |
| [Part 1]CIFAR-10 을 활용한 이미지 생성기 (1) | 2022.02.15 |