
이전 투고에서는 Batch Norm(배치 정규화)이 어떻게 동작하는지 설명하고,
Tensor flow에서 어떻게 사용될 수 있는지를 알아보았습니다.
이번에는 Batch Normalization에 관한 이 시리즈를 완료하기 위해서 기억해야 할 코드를 통해 알아보도록 합시다.
디폴트 상태로 실행했다면 모델의 정확도가 올라가지 않아 BN이 무용지물이 되었을 것인데요. 중요한 하이퍼 파라미터인 BN의 모멘텀을 설정하지 않았기 때문입니다.
Momentum

앞서 설명한 바와 같이, Momentum은 추론을 위한 밀집된 부분의 평균을 계산할 때 이전 이동평균에 주어진 중요성 중요도이다. Momentum이 어떤 건지 모를 경우 Tensorboard에서 조정할 수 있는 것은 Smoothing 뿐이고요. 운동량은 학습 평균과 분산의 "지연"이므로 미니 배치로 인한 노이즈를 무시할 수 있습니다.
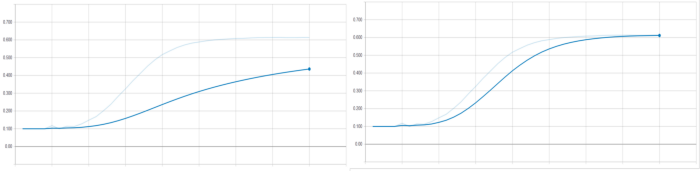
기본적으로 Momentum은 0.99로 높은 값으로 설정되며, 이는 높은 지연과 느린 학습을 의미합니다. 배치 사이즈가 작을 경우, 실행 스텝의 수는 많아집니다. 따라서 운동량이 높으면 이동평균이 느리지게 움직이지만 꾸준한 학습(더 많은 지연)이 발생합니다. 그래서 이런 경우에는 도움이 됩니다.
단, 지금까지 사용한 것처럼 배치 사이즈가 클수록 (50,000개 중) 5,000개의 이미지를 한 번에 처리하면 스텝 수가 적어집니다. 또한, 미니 배치의 통계는 밀집된 부분의 통계와 거의 같다. 이 경우 평균과 분산이 빠르게 업데이트되도록 운동량이 더 작아야 합니다. 따라서 기본 규칙은 다음과 같습니다.
작은 배치 크기 => 높은 Momentum(0.9 ~ 0.99)
큰 배치 크기 => 낮은 Momentum(0.6 ~ 0.85)
대량의 배치의 경우, 훨씬 더 좋은 방법은 역감쇠 Momuntum입니다. 여기서 모멘텀은 시작할 때 매우 적고 훈련이 진행될 때 계속 증가합니다.
history = tf.layers.batch_normalization(net,
momentum=1 - tf.train.exponential_decay(1., tf.train.get_global_step(),10, 0.8),
training=mode == tf.estimator.ModeKeys.TRAIN)Scale and Shift
Scale과 shift parameter는 정규화된 값에 적용되어 분포를 약 0에서 멀리 이동합니다. 활성화되기 전에 BN를 사용하는 경우에 많은 도움이 되며, 현재 BN은 활성화 후 광범위하게 적용되고 있기 때문에 파라미터는 무시될 수 있습니다. 이를 위한 Tensorflow 방법은 다음과 같습니다.
history = tf.layers.batch_normalization(net,
center=False,
scale=False,
momentum=params['momentum'],
training=mode == tf.estimator.ModeKeys.TRAIN)
차이점은 batch_norm 레이어마다 2개의 추가 파라미터를 학습할 필요가 없기 때문에 추가 속도가 향상된다는 것입니다. 또한 파라미터가 적어지고 모델도 얇아집니다.
BN 비선형성 전 => Scale 과 shift 사용
BN 비선형성 후 => Scale 과 shift 비사용
BatchNorm and Dropout
지금까지 Batch 정규화만 사용했으며 모델이 데이터를 overfit 하는 것을 확인했습니다. 또, BN은 약한 정규화에만 사용 가능하며 드롭아웃은 다른 정규화와 함께 사용할 필요가 있습니다.
그런데 Dropout과 BatchNorm을 어떻게 함께 사용할까?
Disharmony between Dropout and Batch Normalization - 이 문서에서는 드롭아웃과 BN을 병용할 때 발생하는 문제에 대한 논문입니다. 결론은 드롭아웃은 모든 BN 레이어, 즉 최종 밀도 레이어에서만 사용해야 한다는 것이다. 드롭아웃 레이어 뒤에 BatchNorm을 사용하면 안 됩니다.

보시다시피 드롭아웃 후에 BN을 사용하면 정확도가 불안정합니다. 드롭아웃은 네트워크 끝에서 사용해야 합니다. 그 이후에는 BN이 올 수 없습니다.
모든 BN 레이어 뒤에 드롭아웃 사용
Batch Renormalization(배치 재규격화)
배치 재규격화는 배치 크기가 32, 64 등 매우 작을 때 사용되는 또 다른 기술입니다. 미니 배치 평균과 분산을 취하는 것은 오류가 발생하기 쉬우므로 이동 통계량이 훈련 자체를 위해 사용됩니다. 정확한 훈련으로 이어지지만 이동통계에 대한 Momentum과 같은 다른 하이퍼 파라미터 세트를 설정해야 합니다.
Tensorflow에서 배치 renorm을 활성화하려면 renorm 파라미터를 True로 설정하고 renorm_motentum도 설정합니다.
history = tf.layers.batch_normalization(net,
momentum=params['momentum'],
renorm=True,
renorm_momentum=params['rmomentum'],
training=mode == tf.estimator.ModeKeys.TRAIN)작은 배치 크기 => 배치 재규격화 사용
Update moving statistics
Batch Normalization을 사용할 때 잊기 쉬운 중요한 점 중 하나는 훈련 중에 이동평균을 업데이트하는 것을 잊어버린다는 것입니다.
test 할 경우 평균과 분산에 대한 추론 값이 누락되어 정확도가 낮습니다.
Tensorflow에서 업데이트 ops를 train에 추가합니다.
adam = tf.train.AdamOptimizer()
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = adam.minimize(loss, global_step=tf.train.get_global_step())
요약:
- 상황에 따른 Momentum을 설정
- scale and shift는 필요한 경우에만 사용
- dropout 올바르게 사용: dropout은 모든 BN 레이어 뒤에 적용
- 배치 크기가 매우 작을 경우 배치 재규격화를 사용
- 훈련 중에는 밀집된 부분의 통계를 업데이트
배치 정규화에 대해 알아보았습니다. 모델링에 있어 정말 다양한 방법으로 성능이 향상 가능한 것을 알게 되었는데요.
앞으로 정확성이 높은 딥러닝 모델을 만들어가 봐요~~😀😀
'인공지능' 카테고리의 다른 글
| 뇌과학 인공지능, 인류의 미래를 바꾼다. (1) | 2024.01.09 |
|---|---|
| Keras optimizer 종류|Tensorflow (0) | 2022.04.04 |
| Segmentation map-도로 이미지 만들기|Pix2Pix (0) | 2022.03.24 |
| [Part5]Sketch2Pokemon-학습 및 테스트하기|Pix2Pix (2) | 2022.03.23 |
| [Part4]Sketch2Pokemon-Discriminator구성|Pix2Pix (0) | 2022.03.23 |